Quotes
i. “‘Intuition’ comes first. Reasoning comes second.” (Llewelyn & Doorn, Clinical Psychology: A Very Short Introduction, Oxford University Press)
ii. “We tend to cope with difficulties in ways that are familiar to us — acting in ways that were helpful to us in the past, even if these ways are now ineffective or destructive.” (-ll-)
iii. “We all thrive when given attention, and being encouraged and praised is more effective at changing our behaviour than being punished. The best way to increase the frequency of a behaviour is to reward it.” (-ll-)
iv. “You can’t make people change if they don’t want to, but you can support and encourage them to make changes.” (-ll-)
v. “You shall know a word by the company it keeps” (John Rupert Firth, as quoted in Thierry Poibeau’s Machine Translation, MIT Press).
vi. “The basic narrative of sedentism and agriculture has long survived the mythology that originally supplied its charter. From Thomas Hobbes to John Locke to Giambattista Vico to Lewis Henry Morgan to Friedrich Engels to Herbert Spencer to Oswald Spengler to social Darwinist accounts of social evolution in general, the sequence of progress from hunting and gathering to nomadism to agriculture (and from band to village to town to city) was settled doctrine. Such views nearly mimicked Julius Caesar’s evolutionary scheme from households to kindreds to tribes to peoples to the state (a people living under laws), wherein Rome was the apex […]. Though they vary in details, such accounts record the march of civilization conveyed by most pedagogical routines and imprinted on the brains of schoolgirls and schoolboys throughout the world. The move from one mode of subsistence to the next is seen as sharp and definitive. No one, once shown the techniques of agriculture, would dream of remaining a nomad or forager. Each step is presumed to represent an epoch-making leap in mankind’s well-being: more leisure, better nutrition, longer life expectancy, and, at long last, a settled life that promoted the household arts and the development of civilization. Dislodging this narrative from the world’s imagination is well nigh impossible; the twelve-step recovery program required to accomplish that beggars the imagination. I nevertheless make a small start here. It turns out that the greater part of what we might call the standard narrative has had to be abandoned once confronted with accumulating archaeological evidence.” (James C. Scott, Against the Grain, Yale University Press)
vii. “Thanks to hominids, much of the world’s flora and fauna consist of fire-adapted species (pyrophytes) that have been encouraged by burning. The effects of anthropogenic fire are so massive that they might be judged, in an evenhanded account of the human impact on the natural world, to overwhelm crop and livestock domestications.” (-ll-)
viii. “Most discussions of plant domestication and permanent settlement […] assume without further ado that early peoples could not wait to settle down in one spot. Such an assumption is an unwarranted reading back from the standard discourses of agrarian states stigmatizing mobile populations as primitive. […] Nor should the terms “pastoralist,” “agriculturalist,” “hunter,” or “forager,” at least in their essentialist meanings, be taken for granted. They are better understood as defining a spectrum of subsistence activities, not separate peoples […] A family or village whose crops had failed might turn wholly or in part to herding; pastoralists who had lost their flocks might turn to planting. Whole areas during a drought or wetter period might radically shift their subsistence strategy. To treat those engaged in these different activities as essentially different peoples inhabiting different life worlds is again to read back the much later stigmatization of pastoralists by agrarian states to an era where it makes no sense.” (-ll-)
ix. “Neither holy, nor Roman, nor an empire” (Voltaire, on the Holy Roman Empire, as quoted in Joachim Whaley’s The Holy Roman Empire: A Very Short Introduction, Oxford University Press)
x. “We don’t outgrow difficult conversations or get promoted past them. The best workplaces and most effective organizations have them. The family down the street that everyone thinks is perfect has them. Loving couples and lifelong friends have them. In fact, we can make a reasonable argument that engaging (well) in difficult conversations is a sign of health in a relationship. Relationships that deal productively with the inevitable stresses of life are more durable; people who are willing and able to “stick through the hard parts” emerge with a stronger sense of trust in each other and the relationship, because now they have a track record of having worked through something hard and seen that the relationship survived.” (Stone et al., Difficult Conversations, Penguin Publishing Group)
xi. “[D]ifficult conversations are almost never about getting the facts right. They are about conflicting perceptions, interpretations, and values. […] They are not about what is true, they are about what is important. […] Interpretations and judgments are important to explore. In contrast, the quest to determine who is right and who is wrong is a dead end. […] When competent, sensible people do something stupid, the smartest move is to try to figure out, first, what kept them from seeing it coming and, second, how to prevent the problem from happening again. Talking about blame distracts us from exploring why things went wrong and how we might correct them going forward.” (-ll-)
xii. “[W]e each have different stories about what is going on in the world. […] In the normal course of things, we don’t notice the ways in which our story of the world is different from other people’s. But difficult conversations arise at precisely those points where important parts of our story collide with another person’s story. We assume the collision is because of how the other person is; they assume it’s because of how we are. But really the collision is a result of our stories simply being different, with neither of us realizing it. […] To get anywhere in a disagreement, we need to understand the other person’s story well enough to see how their conclusions make sense within it. And we need to help them understand the story in which our conclusions make sense. Understanding each other’s stories from the inside won’t necessarily “solve” the problem, but […] it’s an essential first step.” (-ll-)
xiii. “I am really nervous about the word “deserve”. In some cosmic sense nobody “deserves” anything – try to tell the universe you don’t deserve to grow old and die, then watch it laugh at [you] as you die anyway.” (Scott Alexander)
xiv. “How we spend our days is, of course, how we spend our lives.” (Annie Dillard)
xv. “If you do not change direction, you may end up where you are heading.” (Lao Tzu)
xvi. “The smart way to keep people passive and obedient is to strictly limit the spectrum of acceptable opinion, but allow very lively debate within that spectrum.” (Chomsky)
xvii. “If we don’t believe in free expression for people we despise, we don’t believe in it at all.” (-ll-)
xviii. “I weigh the man, not his title; ’tis not the king’s stamp can make the metal better.” (William Wycherley)
xix. “Money is the fruit of evil as often as the root of it.” (Henry Fielding)
xx. “To whom nothing is given, of him can nothing be required.” (-ll-)
Algorithms to live by…
“…algorithms are not confined to mathematics alone. When you cook bread from a recipe, you’re following an algorithm. When you knit a sweater from a pattern, you’re following an algorithm. When you put a sharp edge on a piece of flint by executing a precise sequence of strikes with the end of an antler—a key step in making fine stone tools—you’re following an algorithm. Algorithms have been a part of human technology ever since the Stone Age.
* * *
In this book, we explore the idea of human algorithm design—searching for better solutions to the challenges people encounter every day. Applying the lens of computer science to everyday life has consequences at many scales. Most immediately, it offers us practical, concrete suggestions for how to solve specific problems. Optimal stopping tells us when to look and when to leap. The explore/exploit tradeoff tells us how to find the balance between trying new things and enjoying our favorites. Sorting theory tells us how (and whether) to arrange our offices. Caching theory tells us how to fill our closets. Scheduling theory tells us how to fill our time. At the next level, computer science gives us a vocabulary for understanding the deeper principles at play in each of these domains. As Carl Sagan put it, “Science is a way of thinking much more than it is a body of knowledge.” Even in cases where life is too messy for us to expect a strict numerical analysis or a ready answer, using intuitions and concepts honed on the simpler forms of these problems offers us a way to understand the key issues and make progress. […] tackling real-world tasks requires being comfortable with chance, trading off time with accuracy, and using approximations.”
…
I recall Zach Weinersmith recommending the book, and I seem to recall him mentioning when he did so that he’d put off reading it ‘because it sounded like a self-help book’ (paraphrasing). I’m not actually sure how to categorize it but I do know that I really enjoyed it; I gave it five stars on goodreads and added it to my list of favourite books.
The book covers a variety of decision problems and tradeoffs which people face in their every day lives, as well as strategies for how to approach such problems and identify good solutions (if they exist). The explore/exploit tradeoff so often implicitly present (e.g.: ‘when to look for a new restaurant, vs. picking one you are already familiar with’, or perhaps: ‘when to spend time with friends you already know, vs. spending time trying to find new (/better?) friends?’), optimal stopping rules (‘at which point do you stop looking for a romantic partner and decide that ‘this one is the one’?’ – this is perhaps a well-known problem with a well-known solution, but had you considered that you might use the same analytical framework for questions such as: ‘when to stop looking for a better parking spot and just accept that this one is probably the best one you’ll be able to find?’?), sorting problems (good and bad ways of sorting, why sort, when is sorting even necessary/required?, etc.), scheduling theory (how to handle task management in a good way, so that you optimize over a given constraint set – some examples from this part are included in the quotes below), satisficing vs optimizing (heuristics, ‘when less is more’, etc.), etc. The book is mainly a computer science book, but it is also to some extent an implicitly interdisciplinary work covering material from a variety of other areas such as statistics, game theory, behavioral economics and psychology. There is a major focus throughout on providing insights which are actionable and can actually be used by the reader, e.g. through the translation of identified solutions to heuristics which might be applied in every day life. The book is more pop-science-like than any book I’d have liked to read 10 years ago, and there are too many personal anecdotes for my taste included, but in some sense this never felt like a major issue while I was reading; a lot of interesting ideas and topics are covered, and the amount of fluff is within acceptable limits – a related point is also that the ‘fluff’ is also part of what makes the book relevant, because the authors really focus on tradeoffs and problems which really are highly relevant to some potentially key aspects of most people’s lives, including their own.
Below I have added some sample quotes from the book. If you like the quotes you’ll like the book, it’s full of this kind of stuff. I definitely recommend it to anyone remotely interested in decision theory and related topics.
…
“…one of the deepest truths of machine learning is that, in fact, it’s not always better to use a more complex model, one that takes a greater number of factors into account. And the issue is not just that the extra factors might offer diminishing returns—performing better than a simpler model, but not enough to justify the added complexity. Rather, they might make our predictions dramatically worse. […] overfitting poses a danger every time we’re dealing with noise or mismeasurement – and we almost always are. […] Many prediction algorithms […] start out by searching for the single most important factor rather than jumping to a multi-factor model. Only after finding that first factor do they look for the next most important factor to add to the model, then the next, and so on. Their models can therefore be kept from becoming overly complex simply by stopping the process short, before overfitting has had a chance to creep in. […] This kind of setup — where more time means more complexity — characterizes a lot of human endeavors. Giving yourself more time to decide about something does not necessarily mean that you’ll make a better decision. But it does guarantee that you’ll end up considering more factors, more hypotheticals, more pros and cons, and thus risk overfitting. […] The effectiveness of regularization in all kinds of machine-learning tasks suggests that we can make better decisions by deliberately thinking and doing less. If the factors we come up with first are likely to be the most important ones, then beyond a certain point thinking more about a problem is not only going to be a waste of time and effort — it will lead us to worse solutions. […] sometimes it’s not a matter of choosing between being rational and going with our first instinct. Going with our first instinct can be the rational solution. The more complex, unstable, and uncertain the decision, the more rational an approach that is.” (…for more on these topics I recommend Gigerenzer)
“If you’re concerned with minimizing maximum lateness, then the best strategy is to start with the task due soonest and work your way toward the task due last. This strategy, known as Earliest Due Date, is fairly intuitive. […] Sometimes due dates aren’t our primary concern and we just want to get stuff done: as much stuff, as quickly as possible. It turns out that translating this seemingly simple desire into an explicit scheduling metric is harder than it sounds. One approach is to take an outsider’s perspective. We’ve noted that in single-machine scheduling, nothing we do can change how long it will take us to finish all of our tasks — but if each task, for instance, represents a waiting client, then there is a way to take up as little of their collective time as possible. Imagine starting on Monday morning with a four-day project and a one-day project on your agenda. If you deliver the bigger project on Thursday afternoon (4 days elapsed) and then the small one on Friday afternoon (5 days elapsed), the clients will have waited a total of 4 + 5 = 9 days. If you reverse the order, however, you can finish the small project on Monday and the big one on Friday, with the clients waiting a total of only 1 + 5 = 6 days. It’s a full workweek for you either way, but now you’ve saved your clients three days of their combined time. Scheduling theorists call this metric the “sum of completion times.” Minimizing the sum of completion times leads to a very simple optimal algorithm called Shortest Processing Time: always do the quickest task you can. Even if you don’t have impatient clients hanging on every job, Shortest Processing Time gets things done.”
“Of course, not all unfinished business is created equal. […] In scheduling, this difference of importance is captured in a variable known as weight. […] The optimal strategy for [minimizing weighted completion time] is a simple modification of Shortest Processing Time: divide the weight of each task by how long it will take to finish, and then work in order from the highest resulting importance-per-unit-time [..] to the lowest. […] this strategy … offers a nice rule of thumb: only prioritize a task that takes twice as long if it’s twice as important.”
“So far we have considered only factors that make scheduling harder. But there is one twist that can make it easier: being able to stop one task partway through and switch to another. This property, “preemption,” turns out to change the game dramatically. Minimizing maximum lateness … or the sum of completion times … both cross the line into intractability if some tasks can’t be started until a particular time. But they return to having efficient solutions once preemption is allowed. In both cases, the classic strategies — Earliest Due Date and Shortest Processing Time, respectively — remain the best, with a fairly straightforward modification. When a task’s starting time comes, compare that task to the one currently under way. If you’re working by Earliest Due Date and the new task is due even sooner than the current one, switch gears; otherwise stay the course. Likewise, if you’re working by Shortest Processing Time, and the new task can be finished faster than the current one, pause to take care of it first; otherwise, continue with what you were doing.”
“…even if you don’t know when tasks will begin, Earliest Due Date and Shortest Processing Time are still optimal strategies, able to guarantee you (on average) the best possible performance in the face of uncertainty. If assignments get tossed on your desk at unpredictable moments, the optimal strategy for minimizing maximum lateness is still the preemptive version of Earliest Due Date—switching to the job that just came up if it’s due sooner than the one you’re currently doing, and otherwise ignoring it. Similarly, the preemptive version of Shortest Processing Time—compare the time left to finish the current task to the time it would take to complete the new one—is still optimal for minimizing the sum of completion times. In fact, the weighted version of Shortest Processing Time is a pretty good candidate for best general-purpose scheduling strategy in the face of uncertainty. It offers a simple prescription for time management: each time a new piece of work comes in, divide its importance by the amount of time it will take to complete. If that figure is higher than for the task you’re currently doing, switch to the new one; otherwise stick with the current task. This algorithm is the closest thing that scheduling theory has to a skeleton key or Swiss Army knife, the optimal strategy not just for one flavor of problem but for many. Under certain assumptions it minimizes not just the sum of weighted completion times, as we might expect, but also the sum of the weights of the late jobs and the sum of the weighted lateness of those jobs.”
“…preemption isn’t free. Every time you switch tasks, you pay a price, known in computer science as a context switch. When a computer processor shifts its attention away from a given program, there’s always a certain amount of necessary overhead. […] It’s metawork. Every context switch is wasted time. Humans clearly have context-switching costs too. […] Part of what makes real-time scheduling so complex and interesting is that it is fundamentally a negotiation between two principles that aren’t fully compatible. These two principles are called responsiveness and throughput: how quickly you can respond to things, and how much you can get done overall. […] Establishing a minimum amount of time to spend on any one task helps to prevent a commitment to responsiveness from obliterating throughput […] The moral is that you should try to stay on a single task as long as possible without decreasing your responsiveness below the minimum acceptable limit. Decide how responsive you need to be — and then, if you want to get things done, be no more responsive than that. If you find yourself doing a lot of context switching because you’re tackling a heterogeneous collection of short tasks, you can also employ another idea from computer science: “interrupt coalescing.” If you have five credit card bills, for instance, don’t pay them as they arrive; take care of them all in one go when the fifth bill comes.”
Links and random stuff
i. Pulmonary Aspects of Exercise and Sports.
“Although the lungs are a critical component of exercise performance, their response to exercise and other environmental stresses is often overlooked when evaluating pulmonary performance during high workloads. Exercise can produce capillary leakage, particularly when left atrial pressure increases related to left ventricular (LV) systolic or diastolic failure. Diastolic LV dysfunction that results in elevated left atrial pressure during exercise is particularly likely to result in pulmonary edema and capillary hemorrhage. Data from race horses, endurance athletes, and triathletes support the concept that the lungs can react to exercise and immersion stress with pulmonary edema and pulmonary hemorrhage. Immersion in water by swimmers and divers can also increase stress on pulmonary capillaries and result in pulmonary edema.”
“Zavorsksy et al.11 studied individuals under several different workloads and performed lung imaging to document the presence or absence of lung edema. Radiographic image readers were blinded to the exposures and reported visual evidence of lung fluid. In individuals undergoing a diagnostic graded exercise test, no evidence of lung edema was noted. However, 15% of individuals who ran on a treadmill at 70% of maximum capacity for 2 hours demonstrated evidence of pulmonary edema, as did 65% of those who ran at maximum capacity for 7 minutes. Similar findings were noted in female athletes.12 Pingitore et al. examined 48 athletes before and after completing an iron man triathlon. They used ultrasound to detect lung edema and reported the incidence of ultrasound lung comets.13 None of the athletes had evidence of lung edema before the event, while 75% showed evidence of pulmonary edema immediately post-race, and 42% had persistent findings of pulmonary edema 12 hours post-race. Their data and several case reports14–16 have demonstrated that extreme exercise can result in pulmonary edema”
“Conclusions
Sports and recreational participation can result in lung injury caused by high pulmonary pressures and increased blood volume that raises intracapillary pressure and results in capillary rupture with subsequent pulmonary edema and hemorrhage. High-intensity exercise can result in accumulation of pulmonary fluid and evidence of pulmonary edema. Competitive swimming can result in both pulmonary edema related to fluid shifts into the thorax from immersion and elevated LV end diastolic pressure related to diastolic dysfunction, particularly in the presence of high-intensity exercise. […] The most important approach to many of these disorders is prevention. […] Prevention strategies include avoiding extreme exercise, avoiding over hydration, and assuring that inspiratory resistance is minimized.”
…
ii. Some interesting thoughts on journalism and journalists from a recent SSC Open Thread by user ‘Well’ (quotes from multiple comments). His/her thoughts seem to line up well with my own views on these topics, and one of the reasons why I don’t follow the news is that my own answer to the first question posed below is quite briefly that, ‘…well, I don’t’:
“I think a more fundamental problem is the irrational expectation that newsmedia are supposed to be a reliable source of information in the first place. Why do we grant them this make-believe power?
The English and Acting majors who got together to put on the shows in which they pose as disinterested arbiters of truth use lots of smoke and mirror techniques to appear authoritative: they open their programs with regal fanfare, they wear fancy suits, they make sure to talk or write in a way that mimics the disinterestedness of scholarly expertise, they appear with spinning globes or dozens of screens behind them as if they’re omniscient, they adorn their publications in fancy black-letter typefaces and give them names like “Sentinel” and “Observer” and “Inquirer” and “Plain Dealer”, they invented for themselves the title of “journalists” as if they take part in some kind of peer review process… But why do these silly tricks work? […] what makes the press “the press” is the little game of make-believe we play where an English or Acting major puts on a suit, talks with a funny cadence in his voice, sits in a movie set that looks like God’s Control Room, or writes in a certain format, using pseudo-academic language and symbols, and calls himself a “journalist” and we all pretend this person is somehow qualified to tell us what is going on in the world.
Even when the “journalist” is saying things we agree with, why do we participate in this ridiculous charade? […] I’m not against punditry or people putting together a platform to talk about things that happen. I’m against people with few skills other than “good storyteller” or “good writer” doing this while painting themselves as “can be trusted to tell you everything you need to know about anything”. […] Inasumuch as what I’m doing can be called “defending” them, I’d “defend” them not because they are providing us with valuable facts (ha!) but because they don’t owe us facts, or anything coherent, in the first place. It’s not like they’re some kind of official facts-providing service. They just put on clothes to look like one.”
…
iii. Chatham house rule.
…
iv. Sex Determination: Why So Many Ways of Doing It?
“Sexual reproduction is an ancient feature of life on earth, and the familiar X and Y chromosomes in humans and other model species have led to the impression that sex determination mechanisms are old and conserved. In fact, males and females are determined by diverse mechanisms that evolve rapidly in many taxa. Yet this diversity in primary sex-determining signals is coupled with conserved molecular pathways that trigger male or female development. Conflicting selection on different parts of the genome and on the two sexes may drive many of these transitions, but few systems with rapid turnover of sex determination mechanisms have been rigorously studied. Here we survey our current understanding of how and why sex determination evolves in animals and plants and identify important gaps in our knowledge that present exciting research opportunities to characterize the evolutionary forces and molecular pathways underlying the evolution of sex determination.”
…
v. So Good They Can’t Ignore You.
“Cal Newport’s 2012 book So Good They Can’t Ignore You is a career strategy book designed around four ideas.
The first idea is that ‘follow your passion’ is terrible career advice, and people who say this should be shot don’t know what they’re talking about. […] The second idea is that instead of believing in the passion hypothesis, you should adopt what Newport calls the ‘craftsman mindset’. The craftsman mindset is that you should focus on gaining rare and valuable skills, since this is what leads to good career outcomes.
The third idea is that autonomy is the most important component of a ‘dream’ job. Newport argues that when choosing between two jobs, there are compelling reasons to ‘always’ pick the one with higher autonomy over the one with lower autonomy.
The fourth idea is that having a ‘mission’ or a ‘higher purpose’ in your job is probably a good idea, and is really nice if you can find it. […] the book structure is basically: ‘following your passion is bad, instead go for Mastery[,] Autonomy and Purpose — the trio of things that have been proven to motivate knowledge workers’.” […]
“Newport argues that applying deliberate practice to your chosen skill market is your best shot at becoming ‘so good they can’t ignore you’. The key is to stretch — you want to practice skills that are just above your current skill level, so that you experience discomfort — but not too much discomfort that you’ll give up.” […]
“Newport thinks that if your job has one or more of the following qualities, you should leave your job in favour of another where you can build career capital:
- Your job presents few opportunities to distinguish yourself by developing relevant skills that are rare and valuable.
- Your job focuses on something you think is useless or perhaps even actively bad for the world.
- Your job forces you to work with people you really dislike.
If you’re in a job with any of these traits, your ability to gain rare and valuable skills would be hampered. So it’s best to get out.”
…
vi. Structural brain imaging correlates of general intelligence in UK Biobank.
“The association between brain volume and intelligence has been one of the most regularly-studied—though still controversial—questions in cognitive neuroscience research. The conclusion of multiple previous meta-analyses is that the relation between these two quantities is positive and highly replicable, though modest (Gignac & Bates, 2017; McDaniel, 2005; Pietschnig, Penke, Wicherts, Zeiler, & Voracek, 2015), yet its magnitude remains the subject of debate. The most recent meta-analysis, which included a total sample size of 8036 participants with measures of both brain volume and intelligence, estimated the correlation at r = 0.24 (Pietschnig et al., 2015). A more recent re-analysis of the meta-analytic data, only including healthy adult samples (N = 1758), found a correlation of r = 0.31 (Gignac & Bates, 2017). Furthermore, the correlation increased as a function of intelligence measurement quality: studies with better-quality intelligence tests—for instance, those including multiple measures and a longer testing time—tended to produce even higher correlations with brain volume (up to 0.39). […] Here, we report an analysis of data from a large, single sample with high-quality MRI measurements and four diverse cognitive tests. […] We judge that the large N, study homogeneity, and diversity of cognitive tests relative to previous large scale analyses provides important new evidence on the size of the brain structure-intelligence correlation. By investigating the relations between general intelligence and characteristics of many specific regions and subregions of the brain in this large single sample, we substantially exceed the scope of previous meta-analytic work in this area. […]
“We used a large sample from UK Biobank (N = 29,004, age range = 44–81 years). […] This preregistered study provides a large single sample analysis of the global and regional brain correlates of a latent factor of general intelligence. Our study design avoids issues of publication bias and inconsistent cognitive measurement to which meta-analyses are susceptible, and also provides a latent measure of intelligence which compares favourably with previous single-indicator studies of this type. We estimate the correlation between total brain volume and intelligence to be r = 0.276, which applies to both males and females. Multiple global tissue measures account for around double the variance in g in older participants, relative to those in middle age. Finally, we find that associations with intelligence were strongest in frontal, insula, anterior and medial temporal, lateral occipital and paracingulate cortices, alongside subcortical volumes (especially the thalamus) and the microstructure of the thalamic radiations, association pathways and forceps minor.”
…
vii. Another IQ study: Low IQ as a predictor of unsuccessful educational and occupational achievement: A register-based study of 1,098,742 men in Denmark 1968–2016.
“Intelligence test score is a well-established predictor of educational and occupational achievement worldwide […]. Longitudinal studies typically report cor-relation coefficients of 0.5–0.6 between intelligence and educational achievement as assessed by educational level or school grades […], correlation coefficients of 0.4–0.5 between intelligence and occupational level […] and cor-relation coefficients of 0.2–0.4 between intelligence and income […]. Although the above-mentioned associations are well-established, low intelligence still seems to be an overlooked problem among young people struggling to complete an education or gain a foothold in the labour market […] Due to contextual differences with regard to educational system and flexibility and security on the labour market as well as educational and labour market policies, the role of intelligence in predicting unsuccessful educational and occupational courses may vary among countries. As Denmark has free admittance to education at all levels, state financed student grants for all students, and a relatively high support of students with special educational needs, intelligence might be expected to play a larger role – as socioeconomic factors might be of less importance – with regard to educational and occupational achievement compared with countries outside Scandinavia. The aim of this study was therefore to investigate the role of IQ in predicting a wide range of indicators of unsuccessful educational and occupational achievement among young people born across five decades in Denmark.”
“Individuals who differed in IQ score were found to differ with regard to all indicators of unsuccessful educational and occupational achievement such that low IQ was associated with a higher proportion of unsuccessful educational and occupational achievement. For example, among the 12.1% of our study population who left lower secondary school without receiving a certificate, 39.7% had an IQ < 80 and 23.1% had an IQ of 80–89, although these individuals only accounted for 7.8% and 13.1% of the total study population. The main analyses showed that IQ was inversely associated with all indicators of unsuccessful educational and occupational achievement in young adulthood after adjustment for covariates […] With regard to unsuccessful educational achievement, […] the probabilities of no school leaving certificate, no youth education at age 25, and no vocational qualification at age 30 decreased with increasing IQ in a cubic relation, suggesting essentially no or only weak associations at superior IQ levels. IQ had the strongest influence on the probability of no school leaving certificate. Although the probabilities of the three outcome indicators were almost the same among individuals with extremely low IQ, the probability of no school leaving certificate approached zero among individuals with an IQ of 100 or above whereas the probabilities of no youth education at age 25 and no vocational qualification at age 30 remained notably higher. […] individuals with an IQ of 70 had a median gross income of 301,347 DKK, individuals with an IQ of 100 had a median gross income of 331,854, and individuals with an IQ of 130 had a median gross income of 363,089 DKK – in the beginning of June 2018 corresponding to about 47,856 USD, 52,701 USD, and 57,662 USD, respectively. […] The results showed that among individuals undergoing education, low IQ was associated with a higher hazard rate of passing to employment, unemployment, sickness benefits receipt and welfare benefits receipt […]. This indicates that individuals with low IQ tend to leave the educational system to find employment at a younger age than individuals with high IQ, but that this early leave from the educational system often is associated with a transition into unemployment, sickness benefits receipt and welfare benefits receipt.”
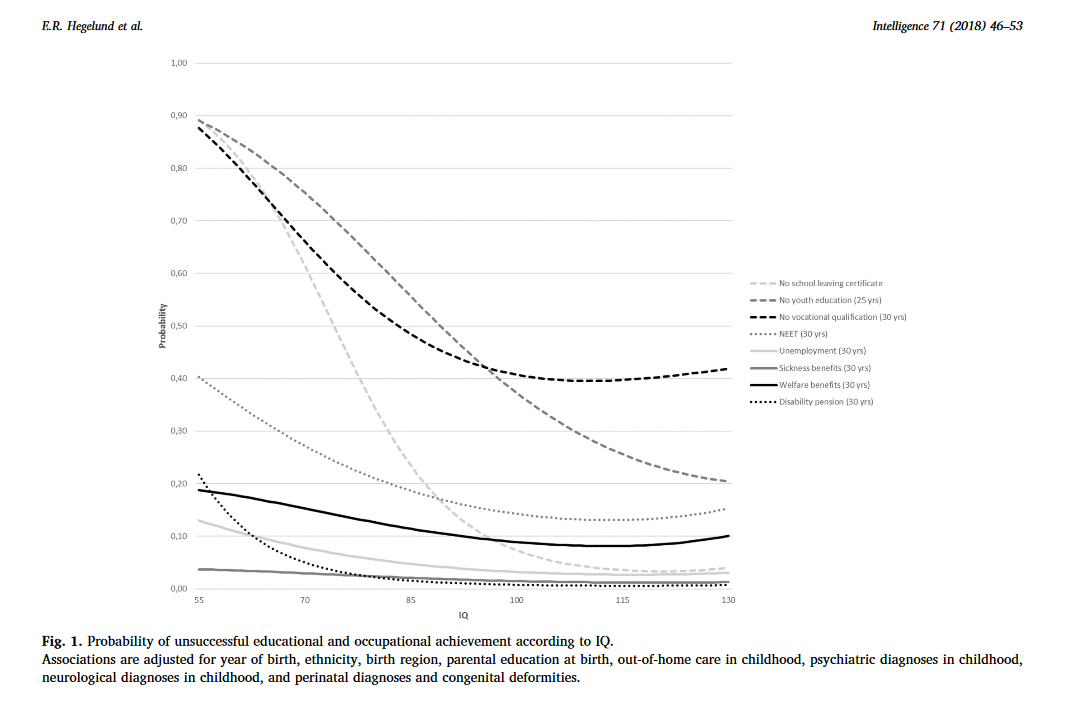
“Conclusions
This study of 1,098,742 Danish men followed in national registers from 1968 to 2016 found that low IQ was a strong and consistent predictor of 10 indicators of unsuccessful educational and occupational achievement in young adulthood. Overall, it seemed that IQ had the strongest influence on the risk of unsuccessful educational achievement and on the risk of disability pension, and that the influence of IQ on educational achievement was strongest in the early educational career and decreased over time. At the community level our findings suggest that intelligence should be considered when planning interventions to reduce the rates of early school leaving and the unemployment rates and at the individual level our findings suggest that assessment of intelligence may provide crucial information for the counselling of poor-functioning schoolchildren and adolescents with regard to both the immediate educational goals and the more distant work-related future.”
Dyslexia (I)
A few years back I started out on another publication edited by the same author, the Wiley-Blackwell publication The Science of Reading: A Handbook. That book is dense and in the end I decided it wasn’t worth it to finish it – but I also learned from reading it that Snowling, the author of this book, probably knows her stuff. This book only covers a limited range of the literature on reading, but an interesting one.
I have added some quotes and links from the first chapters of the book below.
…
“Literacy difficulties, when they are not caused by lack of education, are known as dyslexia. Dyslexia can be defined as a problem with learning which primarily affects the development of reading accuracy and fluency and spelling skills. Dyslexia frequently occurs together with other difficulties, such as problems in attention, organization, and motor skills (movement) but these are not in and of themselves indicators of dyslexia. […] at the core of the problem is a difficulty in decoding words for reading and encoding them for spelling. Fluency in these processes is never achieved. […] children with specific reading difficulties show a poor response to reading instruction […] ‘response to intervention’ has been proposed as a better way of identifying likely dyslexic difficulties than measured reading skills. […] To this day, there is tension between the medical model of ‘dyslexia’ and the understanding of ‘specific learning difficulties’ in educational circles. The nub of the problem for the concept of dyslexia is that, unlike measles or chicken pox, it is not a disorder with a clear diagnostic profile. Rather, reading skills are distributed normally in the population […] dyslexia is like high blood pressure, there is no precise cut-off between high blood pressure and ‘normal’ blood pressure, but if high blood pressure remains untreated, the risk of complications is high. Hence, a diagnosis of ‘hypertension’ is warranted […] this book will show that there is remarkable agreement among researchers regarding the risk factors for poor reading and a growing number of evidence-based interventions: dyslexia definitely exists and we can do a great deal to ameliorate its effects”.
“An obvious though not often acknowledged fact is that literacy builds on a foundation of spoken language—indeed, an assumption of all education systems is that, when a child starts school, their spoken language is sufficient to support reading development. […] many children start school with considerable knowledge about books: they know that print runs from left to right (at least if you are reading English) and that you read from the front to the back of the book; and they are familiar with at least some letter names or sounds. At a basic level, reading involves translating printed symbols into pronunciations—a task referred to as decoding, which requires mapping across modalities from vision (written forms) to audition (spoken sounds). Beyond knowing letters, the beginning reader has to discover how printed words relate to spoken words and a major aim of reading instruction is to help the learner to ‘crack’ this code. To decode in English (and other alphabetic languages) requires learning about ‘grapheme–phoneme’ correspondences—literally the way in which letters or letter combinations relate to the speech sounds of spoken words: this is not a trivial task. When children use language naturally, they have only implicit knowledge of the words they use and they do not pay attention to their sounds; but this is precisely what they need to do in order to learn to decode. Indeed, they have to become ‘aware’ that words can be broken down into constituent parts like the syllable […] and that, in turn, syllables can be segmented into phonemes […]. Phonemes are the smallest sounds which differentiate words; for example, ‘pit’ and ‘bit’ differ by a single phoneme [b]-[p] (in fact, both are referred to as ‘stop consonants’ and they differ only by a single phonemic feature, namely the timing of the voicing onset of the consonant). In the English writing system, phonemes are the units which are coded in the grapheme-correspondences that make up the orthographic code.”
“The term ‘phoneme awareness‘ refers to the ability to reflect on and manipulate the speech sounds in words. It is a metalinguistic skill (a skill requiring conscious control of language) which develops after the ability to segment words into syllables and into rhyming parts […]. There has been controversy over whether phoneme awareness is a cause or a consequence of learning to read. […] In general, letters are easier to learn (being concrete) than phoneme awareness is to acquire (being an abstract skill). […] The acquisition of ‘phoneme awareness’ is a critical step in the development of decoding skills. A typical reader who possesses both letter knowledge and phoneme awareness can readily ‘sound out’ letters and blend the sounds together to read words or even meaningless but pronounceable letter strings (nonwords); conversely, they can split up words (segment them) into sounds for spelling. When these building blocks are in place, a child has developed ‘alphabetic competence’ and the task of becoming a reader can begin properly. […[ Another factor which is important in promoting reading fluency is the size of a child’s vocabulary. […] children with poor oral language skills, specifically limited semantic knowledge of words, [have e.g. been shown to have] particular difficulty in reading irregular words. […] Essentially, reading is a ‘big data’ problem—the task of learning involves extracting the statistical relationships between spelling (orthography) and sound (phonology) and using these to develop an algorithm for reading which is continually refined as further words are encountered.”
“It is commonly believed that spelling is simply the reverse of reading. It is not. As a consequence, learning to read does not always bring with it spelling proficiency. One reason is that the correspondences between letters and sounds used for reading (grapheme–phoneme correspondences) are not just the same as the sound-to-letter rules used for writing (phoneme–grapheme correspondences). Indeed, in English, the correspondences used in reading are generally more consistent than those used in spelling […] many of the early spelling errors children make replicate errors observed in speech development […] Children with dyslexia often struggle to spell words phonetically […] The relationship between phoneme awareness and letter knowledge at age 4 and phonological accuracy of spelling attempts at age 5 has been studied longitudinally with the aim of understanding individual differences in children’s spelling skills. As expected, these two components of alphabetic knowledge predicted the phonological accuracy of children’s early spelling. In turn, children’s phonological spelling accuracy along with their reading skill at this early stage predicted their spelling proficiency after three years in school. The findings suggest that the ability to transcode phonologically provides a foundation for the development of orthographic representations for spelling but this alone is not enough—information acquired from reading experience is required to ensure spellings are conventionally correct. […] for spelling as for reading, practice is important.”
“Irrespective of the language, reading involves mapping between the visual symbols of words and their phonological forms. What differs between languages is the nature of the symbols and the phonological units. Indeed, the mappings which need to be created are at different levels of ‘grain size’ in different languages (fine-grained in alphabets which connect letters and sounds like German or Italian, and more coarse-grained in logographic systems like Chinese that map between characters and syllabic units). Languages also differ in the complexity of their morphology and how this maps to the orthography. Among the alphabetic languages, English is the least regular, particularly for spelling; the most regular is Finnish with a completely transparent system of mappings between letters and phonemes […]. The term ‘orthographic depth’ is used to describe the level of regularity which is observed between languages — English is opaque (or deep), followed by Danish and French which also contain many irregularities, while Spanish and Italian rank among the more regular, transparent (or shallow) orthographies. Over the years, there has been much discussion as to whether children learning to read English have a particularly tough task and there is frequent speculation that dyslexia is more prevalent in English than in other languages. There is no evidence that this is the case. But what is clear is that it takes longer to become a fluent reader of English than of a more transparent language […] There are reasons other than orthographic consistency which make languages easier or harder to learn. One of these is the number of symbols in the writing system: the European languages have fewer than 35 while others have as many as 2,500. For readers of languages with extensive symbolic systems like Chinese, which has more than 2,000 characters, learning can be expected to continue through the middle and high school years. The visual-spatial complexity of the symbols may add further to the burden of learning. […] when there are more symbols in a writing system, the learning demands increase. […] Languages also differ importantly in the ways they represent phonology and meaning.”
“Given the many differences between languages and writing systems, there is remarkable similarity between the predictors of individual differences in reading across languages. The ELDEL study showed that for children reading alphabetic languages there are three significant predictors of growth in reading in the early years of schooling. These are letter knowledge, phoneme awareness, and rapid naming (a test in which the names of colours or objects have to be produced as quickly as possible in response to a random array of such items). Researchers have shown that a similar set of skills predict reading in Chinese […] However, there are also additional predictors that are language-specific. […] visual memory and visuo-spatial skills are stronger predictors of learning to read in a visually complex writing system, such as Chinese or Kannada, than they are for English. Moreover, there is emerging evidence of reciprocal relations – that learning to read in a complex orthography hones visuo-spatial abilities just as phoneme awareness improves as English children learn to read.”
“Children differ in the rate at which they learn to read and spell and children with dyslexia are typically the slowest to do so, assuming standard instruction for all. Indeed, it is clear from the outset that they have more difficulty in learning letters (by name or by sound) than their peers. As we have seen, letter knowledge is a crucial component of alphabetic competence and also offers a way into spelling. So for the dyslexic child with poor letter knowledge, learning to read and spell is compromised from the outset. In addition, there is a great deal of evidence that children with dyslexia have problems with phonological aspects of language from an early age and specifically, acquiring phonological awareness. […] The result is usually a significant problem in decoding—in fact, poor decoding is the hallmark of dyslexia, the signature of which is a nonword reading deficit. In the absence of remediation, this decoding difficulty persists and for many reading becomes something to be avoided. […] the most common pattern of reading deficit in dyslexia is an inability to read ‘new’ or unfamiliar words in the face of better developed word-reading skills — sometimes referred to as ‘phonological dyslexia’. […] Spelling poses a significant challenge to children with dyslexia. This seems inevitable, given their problems with phoneme awareness and decoding. The early spelling attempts of children with dyslexia are typically not phonetic in the way that their peers’ attempts are; rather, they are often difficult to decipher and best described as bizarre. […] errors continue to reflect profound difficulties in representing the sounds of words […] most people with dyslexia continue to show poor spelling through development and there is a very high correlation between (poor) spelling in the teenage years and (poor) spelling in middle age. […] While poor decoding can be a barrier to reading comprehension, many children and adults with dyslexia can read with adequate understanding when this is required but it takes them considerable time to do so, and they tend to avoid writing when it is possible to do so.”
…
Links:
Phonics.
History of dyslexia research. Samuel Orton. Rudolf Berlin. Anna Gillingham. Orton-Gillingham(-Stillman) approach. Thomas Richard Miles.
Seidenberg & McClelland’s triangle model.
“The Simple View of Reading”.
The lexical quality hypothesis (Perfetti & Hart). Matthew effect.
ELDEL project.
Diacritical mark.
Hiragana.
Phonetic radicals.
Morphogram.
Random stuff
i. Your Care Home in 120 Seconds. Some quotes:
“In order to get an overall estimate of mental power, psychologists have chosen a series of tasks to represent some of the basic elements of problem solving. The selection is based on looking at the sorts of problems people have to solve in everyday life, with particular attention to learning at school and then taking up occupations with varying intellectual demands. Those tasks vary somewhat, though they have a core in common.
Most tests include Vocabulary, examples: either asking for the definition of words of increasing rarity; or the names of pictured objects or activities; or the synonyms or antonyms of words.
Most tests include Reasoning, examples: either determining which pattern best completes the missing cell in a matrix (like Raven’s Matrices); or putting in the word which completes a sequence; or finding the odd word out in a series.
Most tests include visualization of shapes, examples: determining the correspondence between a 3-D figure and alternative 2-D figures; determining the pattern of holes that would result from a sequence of folds and a punch through folded paper; determining which combinations of shapes are needed to fill a larger shape.
Most tests include episodic memory, examples: number of idea units recalled across two or three stories; number of words recalled from across 1 to 4 trials of a repeated word list; number of words recalled when presented with a stimulus term in a paired-associate learning task.
Most tests include a rather simple set of basic tasks called Processing Skills. They are rather humdrum activities, like checking for errors, applying simple codes, and checking for similarities or differences in word strings or line patterns. They may seem low grade, but they are necessary when we try to organise ourselves to carry out planned activities. They tend to decline with age, leading to patchy, unreliable performance, and a tendency to muddled and even harmful errors. […]
A brain scan, for all its apparent precision, is not a direct measure of actual performance. Currently, scans are not as accurate in predicting behaviour as is a simple test of behaviour. This is a simple but crucial point: so long as you are willing to conduct actual tests, you can get a good understanding of a person’s capacities even on a very brief examination of their performance. […] There are several tests which have the benefit of being quick to administer and powerful in their predictions.[..] All these tests are good at picking up illness related cognitive changes, as in diabetes. (Intelligence testing is rarely criticized when used in medical settings). Delayed memory and working memory are both affected during diabetic crises. Digit Symbol is reduced during hypoglycaemia, as are Digits Backwards. Digit Symbol is very good at showing general cognitive changes from age 70 to 76. Again, although this is a limited time period in the elderly, the decline in speed is a notable feature. […]
The most robust and consistent predictor of cognitive change within old age, even after control for all the other variables, was the presence of the APOE e4 allele. APOE e4 carriers showed over half a standard deviation more general cognitive decline compared to noncarriers, with particularly pronounced decline in their Speed and numerically smaller, but still significant, declines in their verbal memory.
It is rare to have a big effect from one gene. Few people carry it, and it is not good to have.“
…
ii. What are common mistakes junior data scientists make?
Apparently the OP had second thoughts about this query so s/he deleted the question and marked the thread nsfw (??? …nothing remotely nsfw in that thread…). Fortunately the replies are all still there, there are quite a few good responses in the thread. I added some examples below:
“I think underestimating the domain/business side of things and focusing too much on tools and methodology. As a fairly new data scientist myself, I found myself humbled during this one project where I had I spent a lot of time tweaking parameters and making sure the numbers worked just right. After going into a meeting about it became clear pretty quickly that my little micro-optimizations were hardly important, and instead there were X Y Z big picture considerations I was missing in my analysis.”
[…]
-
Forgetting to check how actionable the model (or features) are. It doesn’t matter if you have amazing model for cancer prediction, if it’s based on features from tests performed as part of the post-mortem. Similarly, predicting account fraud after the money has been transferred is not going to be very useful.
-
Emphasis on lack of understanding of the business/domain.
-
Lack of communication and presentation of the impact. If improving your model (which is a quarter of the overall pipeline) by 10% in reducing customer churn is worth just ~100K a year, then it may not be worth putting into production in a large company.
-
Underestimating how hard it is to productionize models. This includes acting on the models outputs, it’s not just “run model, get score out per sample”.
-
Forgetting about model and feature decay over time, concept drift.
-
Underestimating the amount of time for data cleaning.
-
Thinking that data cleaning errors will be complicated.
-
Thinking that data cleaning will be simple to automate.
-
Thinking that automation is always better than heuristics from domain experts.
- Focusing on modelling at the expense of [everything] else”
“unhealthy attachments to tools. It really doesn’t matter if you use R, Python, SAS or Excel, did you solve the problem?”
“Starting with actual modelling way too soon: you’ll end up with a model that’s really good at answering the wrong question.
First, make sure that you’re trying to answer the right question, with the right considerations. This is typically not what the client initially told you. It’s (mainly) a data scientist’s job to help the client with formulating the right question.”
…
iii. Some random wikipedia links: Ottoman–Habsburg wars. Planetshine. Anticipation (genetics). Cloze test. Loop quantum gravity. Implicature. Starfish Prime. Stall (fluid dynamics). White Australia policy. Apostatic selection. Deimatic behaviour. Anti-predator adaptation. Lefschetz fixed-point theorem. Hairy ball theorem. Macedonia naming dispute. Holevo’s theorem. Holmström’s theorem. Sparse matrix. Binary search algorithm. Battle of the Bismarck Sea.
…
iv. 5-HTTLPR: A Pointed Review. This one is hard to quote, you should read all of it. I did however decide to add a few quotes from the post, as well as a few quotes from the comments:
“…what bothers me isn’t just that people said 5-HTTLPR mattered and it didn’t. It’s that we built whole imaginary edifices, whole castles in the air on top of this idea of 5-HTTLPR mattering. We “figured out” how 5-HTTLPR exerted its effects, what parts of the brain it was active in, what sorts of things it interacted with, how its effects were enhanced or suppressed by the effects of other imaginary depression genes. This isn’t just an explorer coming back from the Orient and claiming there are unicorns there. It’s the explorer describing the life cycle of unicorns, what unicorns eat, all the different subspecies of unicorn, which cuts of unicorn meat are tastiest, and a blow-by-blow account of a wrestling match between unicorns and Bigfoot.
This is why I start worrying when people talk about how maybe the replication crisis is overblown because sometimes experiments will go differently in different contexts. The problem isn’t just that sometimes an effect exists in a cold room but not in a hot room. The problem is more like “you can get an entire field with hundreds of studies analyzing the behavior of something that doesn’t exist”. There is no amount of context-sensitivity that can help this. […] The problem is that the studies came out positive when they shouldn’t have. This was a perfectly fine thing to study before we understood genetics well, but the whole point of studying is that, once you have done 450 studies on something, you should end up with more knowledge than you started with. In this case we ended up with less. […] I think we should take a second to remember that yes, this is really bad. That this is a rare case where methodological improvements allowed a conclusive test of a popular hypothesis, and it failed badly. How many other cases like this are there, where there’s no geneticist with a 600,000 person sample size to check if it’s true or not? How many of our scientific edifices are built on air? How many useless products are out there under the guise of good science? We still don’t know.”
A few more quotes from the comment section of the post:
“most things that are obviously advantageous or deleterious in a major way aren’t gonna hover at 10%/50%/70% allele frequency.
Population variance where they claim some gene found in > [non trivial]% of the population does something big… I’ll mostly tend to roll to disbelieve.
But if someone claims a family/village with a load of weirdly depressed people (or almost any other disorder affecting anything related to the human condition in any horrifying way you can imagine) are depressed because of a genetic quirk… believable but still make sure they’ve confirmed it segregates with the condition or they’ve got decent backing.
And a large fraction of people have some kind of rare disorder […]. Long tail. Lots of disorders so quite a lot of people with something odd.
It’s not that single variants can’t have a big effect. It’s that really big effects either win and spread to everyone or lose and end up carried by a tiny minority of families where it hasn’t had time to die out yet.
Very few variants with big effect sizes are going to be half way through that process at any given time.
Exceptions are
1: mutations that confer resistance to some disease as a tradeoff for something else […] 2: Genes that confer a big advantage against something that’s only a very recent issue.”
“I think the summary could be something like:
A single gene determining 50% of the variance in any complex trait is inherently atypical, because variance depends on the population plus environment and the selection for such a gene would be strong, rapidly reducing that variance.
However, if the environment has recently changed or is highly variable, or there is a trade-off against adverse effects it is more likely.
Furthermore – if the test population is specifically engineered to target an observed trait following an apparently Mendelian inheritance pattern – such as a family group or a small genetically isolated population plus controls – 50% of the variance could easily be due to a single gene.”
…
“The most over-used and under-analyzed statement in the academic vocabulary is surely “more research is needed”. These four words, occasionally justified when they appear as the last sentence in a Masters dissertation, are as often to be found as the coda for a mega-trial that consumed the lion’s share of a national research budget, or that of a Cochrane review which began with dozens or even hundreds of primary studies and progressively excluded most of them on the grounds that they were “methodologically flawed”. Yet however large the trial or however comprehensive the review, the answer always seems to lie just around the next empirical corner.
With due respect to all those who have used “more research is needed” to sum up months or years of their own work on a topic, this ultimate academic cliché is usually an indicator that serious scholarly thinking on the topic has ceased. It is almost never the only logical conclusion that can be drawn from a set of negative, ambiguous, incomplete or contradictory data.” […]
“Here is a quote from a typical genome-wide association study:
“Genome-wide association (GWA) studies on coronary artery disease (CAD) have been very successful, identifying a total of 32 susceptibility loci so far. Although these loci have provided valuable insights into the etiology of CAD, their cumulative effect explains surprisingly little of the total CAD heritability.” [1]
The authors conclude that not only is more research needed into the genomic loci putatively linked to coronary artery disease, but that – precisely because the model they developed was so weak – further sets of variables (“genetic, epigenetic, transcriptomic, proteomic, metabolic and intermediate outcome variables”) should be added to it. By adding in more and more sets of variables, the authors suggest, we will progressively and substantially reduce the uncertainty about the multiple and complex gene-environment interactions that lead to coronary artery disease. […] We predict tomorrow’s weather, more or less accurately, by measuring dynamic trends in today’s air temperature, wind speed, humidity, barometric pressure and a host of other meteorological variables. But when we try to predict what the weather will be next month, the accuracy of our prediction falls to little better than random. Perhaps we should spend huge sums of money on a more sophisticated weather-prediction model, incorporating the tides on the seas of Mars and the flutter of butterflies’ wings? Of course we shouldn’t. Not only would such a hyper-inclusive model fail to improve the accuracy of our predictive modeling, there are good statistical and operational reasons why it could well make it less accurate.”
…
vi. Why software projects take longer than you think – a statistical model.
“Anyone who built software for a while knows that estimating how long something is going to take is hard. It’s hard to come up with an unbiased estimate of how long something will take, when fundamentally the work in itself is about solving something. One pet theory I’ve had for a really long time, is that some of this is really just a statistical artifact.
Let’s say you estimate a project to take 1 week. Let’s say there are three equally likely outcomes: either it takes 1/2 week, or 1 week, or 2 weeks. The median outcome is actually the same as the estimate: 1 week, but the mean (aka average, aka expected value) is 7/6 = 1.17 weeks. The estimate is actually calibrated (unbiased) for the median (which is 1), but not for the the mean.
A reasonable model for the “blowup factor” (actual time divided by estimated time) would be something like a log-normal distribution. If the estimate is one week, then let’s model the real outcome as a random variable distributed according to the log-normal distribution around one week. This has the property that the median of the distribution is exactly one week, but the mean is much larger […] Intuitively the reason the mean is so large is that tasks that complete faster than estimated have no way to compensate for the tasks that take much longer than estimated. We’re bounded by 0, but unbounded in the other direction.”
I like this way to conceptually frame the problem, and I definitely do not think it only applies to software development.
“I filed this in my brain under “curious toy models” for a long time, occasionally thinking that it’s a neat illustration of a real world phenomenon I’ve observed. But surfing around on the interwebs one day, I encountered an interesting dataset of project estimation and actual times. Fantastic! […] The median blowup factor turns out to be exactly 1x for this dataset, whereas the mean blowup factor is 1.81x. Again, this confirms the hunch that developers estimate the median well, but the mean ends up being much higher. […]
If my model is right (a big if) then here’s what we can learn:
- People estimate the median completion time well, but not the mean.
- The mean turns out to be substantially worse than the median, due to the distribution being skewed (log-normally).
- When you add up the estimates for n tasks, things get even worse.
- Tasks with the most uncertainty (rather the biggest size) can often dominate the mean time it takes to complete all tasks.”
…
vii. Attraction inequality and the dating economy.
“…the relentless focus on inequality among politicians is usually quite narrow: they tend to consider inequality only in monetary terms, and to treat “inequality” as basically synonymous with “income inequality.” There are so many other types of inequality that get air time less often or not at all: inequality of talent, height, number of friends, longevity, inner peace, health, charm, gumption, intelligence, and fortitude. And finally, there is a type of inequality that everyone thinks about occasionally and that young single people obsess over almost constantly: inequality of sexual attractiveness. […] One of the useful tools that economists use to study inequality is the Gini coefficient. This is simply a number between zero and one that is meant to represent the degree of income inequality in any given nation or group. An egalitarian group in which each individual has the same income would have a Gini coefficient of zero, while an unequal group in which one individual had all the income and the rest had none would have a Gini coefficient close to one. […] Some enterprising data nerds have taken on the challenge of estimating Gini coefficients for the dating “economy.” […] The Gini coefficient for [heterosexual] men collectively is determined by [-ll-] women’s collective preferences, and vice versa. If women all find every man equally attractive, the male dating economy will have a Gini coefficient of zero. If men all find the same one woman attractive and consider all other women unattractive, the female dating economy will have a Gini coefficient close to one.”
“A data scientist representing the popular dating app “Hinge” reported on the Gini coefficients he had found in his company’s abundant data, treating “likes” as the equivalent of income. He reported that heterosexual females faced a Gini coefficient of 0.324, while heterosexual males faced a much higher Gini coefficient of 0.542. So neither sex has complete equality: in both cases, there are some “wealthy” people with access to more romantic experiences and some “poor” who have access to few or none. But while the situation for women is something like an economy with some poor, some middle class, and some millionaires, the situation for men is closer to a world with a small number of super-billionaires surrounded by huge masses who possess almost nothing. According to the Hinge analyst:
On a list of 149 countries’ Gini indices provided by the CIA World Factbook, this would place the female dating economy as 75th most unequal (average—think Western Europe) and the male dating economy as the 8th most unequal (kleptocracy, apartheid, perpetual civil war—think South Africa).”
Btw., I’m reasonably certain “Western Europe” as most people think of it is not average in terms of Gini, and that half-way down the list should rather be represented by some other region or country type, like, say Mongolia or Bulgaria. A brief look at Gini lists seemed to support this impression.
“Quartz reported on this finding, and also cited another article about an experiment with Tinder that claimed that that “the bottom 80% of men (in terms of attractiveness) are competing for the bottom 22% of women and the top 78% of women are competing for the top 20% of men.” These studies examined “likes” and “swipes” on Hinge and Tinder, respectively, which are required if there is to be any contact (via messages) between prospective matches. […] Yet another study, run by OkCupid on their huge datasets, found that women rate 80 percent of men as “worse-looking than medium,” and that this 80 percent “below-average” block received replies to messages only about 30 percent of the time or less. By contrast, men rate women as worse-looking than medium only about 50 percent of the time, and this 50 percent below-average block received message replies closer to 40 percent of the time or higher.
If these findings are to be believed, the great majority of women are only willing to communicate romantically with a small minority of men while most men are willing to communicate romantically with most women. […] It seems hard to avoid a basic conclusion: that the majority of women find the majority of men unattractive and not worth engaging with romantically, while the reverse is not true. Stated in another way, it seems that men collectively create a “dating economy” for women with relatively low inequality, while women collectively create a “dating economy” for men with very high inequality.”
…
I think the author goes a bit off the rails later in the post, but the data is interesting. It’s however important keeping in mind in contexts like these that sexual selection pressures apply at multiple levels, not just one, and that partner preferences can be non-trivial to model satisfactorily; for example as many women have learned the hard way, males may have very different standards for whom to a) ‘engage with romantically’ and b) ‘consider a long-term partner’.
…
viii. Flipping the Metabolic Switch: Understanding and Applying Health Benefits of Fasting.
“Intermittent fasting (IF) is a term used to describe a variety of eating patterns in which no or few calories are consumed for time periods that can range from 12 hours to several days, on a recurring basis. Here we focus on the physiological responses of major organ systems, including the musculoskeletal system, to the onset of the metabolic switch – the point of negative energy balance at which liver glycogen stores are depleted and fatty acids are mobilized (typically beyond 12 hours after cessation of food intake). Emerging findings suggest the metabolic switch from glucose to fatty acid-derived ketones represents an evolutionarily conserved trigger point that shifts metabolism from lipid/cholesterol synthesis and fat storage to mobilization of fat through fatty acid oxidation and fatty-acid derived ketones, which serve to preserve muscle mass and function. Thus, IF regimens that induce the metabolic switch have the potential to improve body composition in overweight individuals. […] many experts have suggested IF regimens may have potential in the treatment of obesity and related metabolic conditions, including metabolic syndrome and type 2 diabetes.(20)”
“In most studies, IF regimens have been shown to reduce overall fat mass and visceral fat both of which have been linked to increased diabetes risk.(139) IF regimens ranging in duration from 8 to 24 weeks have consistently been found to decrease insulin resistance.(12, 115, 118, 119, 122, 123, 131, 132, 134, 140) In line with this, many, but not all,(7) large-scale observational studies have also shown a reduced risk of diabetes in participants following an IF eating pattern.”
“…we suggest that future randomized controlled IF trials should use biomarkers of the metabolic switch (e.g., plasma ketone levels) as a measure of compliance and the magnitude of negative energy balance during the fasting period. It is critical for this switch to occur in order to shift metabolism from lipidogenesis (fat storage) to fat mobilization for energy through fatty acid β-oxidation. […] As the health benefits and therapeutic efficacies of IF in different disease conditions emerge from RCTs, it is important to understand the current barriers to widespread use of IF by the medical and nutrition community and to develop strategies for broad implementation. One argument against IF is that, despite the plethora of animal data, some human studies have failed to show such significant benefits of IF over CR [Calorie Restriction].(54) Adherence to fasting interventions has been variable, some short-term studies have reported over 90% adherence,(54) whereas in a one year ADMF study the dropout rate was 38% vs 29% in the standard caloric restriction group.(135)”
…
ix. Self-repairing cells: How single cells heal membrane ruptures and restore lost structures.
Artificial intelligence (I?)
This book was okay, but nothing all that special. In my opinion there’s too much philosophy and similar stuff in there (‘what does intelligence really mean anyway?’), and the coverage isn’t nearly as focused on technological aspects as e.g. Winfield’s (…in my opinion better…) book from the same series on robotics (which I covered here) was; I am certain I’d have liked this book better if it’d provided a similar type of coverage as did Winfield, but it didn’t. However it’s far from terrible and I liked the authors skeptical approach to e.g. singularitarianism. Below I have added some quotes and links, as usual.
…
“Artificial intelligence (AI) seeks to make computers do the sorts of things that minds can do. Some of these (e.g. reasoning) are normally described as ‘intelligent’. Others (e.g. vision) aren’t. But all involve psychological skills — such as perception, association, prediction, planning, motor control — that enable humans and animals to attain their goals. Intelligence isn’t a single dimension, but a richly structured space of diverse information-processing capacities. Accordingly, AI uses many different techniques, addressing many different tasks. […] although AI needs physical machines (i.e. computers), it’s best thought of as using what computer scientists call virtual machines. A virtual machine isn’t a machine depicted in virtual reality, nor something like a simulated car engine used to train mechanics. Rather, it’s the information-processing system that the programmer has in mind when writing a program, and that people have in mind when using it. […] Virtual machines in general are comprised of patterns of activity (information processing) that exist at various levels. […] the human mind can be understood as the virtual machine – or rather, the set of mutually interacting virtual machines, running in parallel […] – that is implemented in the brain. Progress in AI requires progress in defining interesting/useful virtual machines. […] How the information is processed depends on the virtual machine involved. [There are many different approaches.] […] In brief, all the main types of AI were being thought about, and even implemented, by the late 1960s – and in some cases, much earlier than that. […] Neural networks are helpful for modelling aspects of the brain, and for doing pattern recognition and learning. Classical AI (especially when combined with statistics) can model learning too, and also planning and reasoning. Evolutionary programming throws light on biological evolution and brain development. Cellular automata and dynamical systems can be used to model development in living organisms. Some methodologies are closer to biology than to psychology, and some are closer to non-reflective behaviour than to deliberative thought. To understand the full range of mentality, all of them will be needed […]. Many AI researchers [however] don’t care about how minds work: they seek technological efficiency, not scientific understanding. […] In the 21st century, […] it has become clear that different questions require different types of answers”.
“State-of-the-art AI is a many-splendoured thing. It offers a profusion of virtual machines, doing many different kinds of information processing. There’s no key secret here, no core technique unifying the field: AI practitioners work in highly diverse areas, sharing little in terms of goals and methods. […] A host of AI applications exist, designed for countless specific tasks and used in almost every area of life, by laymen and professionals alike. Many outperform even the most expert humans. In that sense, progress has been spectacular. But the AI pioneers weren’t aiming only for specialist systems. They were also hoping for systems with general intelligence. Each human-like capacity they modelled — vision, reasoning, language, learning, and so on — would cover its entire range of challenges. Moreover, these capacities would be integrated when appropriate. Judged by those criteria, progress has been far less impressive. […] General intelligence is still a major challenge, still highly elusive. […] problems can’t always be solved merely by increasing computer power. New problem-solving methods are often needed. Moreover, even if a particular method must succeed in principle, it may need too much time and/or memory to succeed in practice. […] Efficiency is important, too: the fewer the number of computations, the better. In short, problems must be made tractable. There are several basic strategies for doing that. All were pioneered by classical symbolic AI, or GOFAI, and all are still essential today. One is to direct attention to only a part of the search space (the computer’s representation of the problem, within which the solution is assumed to be located). Another is to construct a smaller search space by making simplifying assumptions. A third is to order the search efficiently. Yet another is to construct a different search space, by representing the problem in a new way. These approaches involve heuristics, planning, mathematical simplification, and knowledge representation, respectively. […] Often, the hardest part of AI problem solving is presenting the problem to the system in the first place. […] the information (‘knowledge’) concerned must be presented to the system in a fashion that the machine can understand – in other words, that it can deal with. […] AI’s way of doing this are highly diverse.”
“The rule-baed form of knowledge representation enables programs to be built gradually, as the programmer – or perhaps an AGI system itself – learns more about the domain. A new rule can be added at any time. There’s no need to rewrite the program from scratch. However, there’s a catch. If the new rule isn’t logically consistent with the existing ones, the system won’t always do what it’s supposed to do. It may not even approximate what it’s supposed to do. When dealing with a small set of rules, such logical conflicts are easily avoided, but larger systems are less transparent. […] An alternative form of knowledge representation for concepts is semantic networks […] A semantic network links concepts by semantic relations […] semantic networks aren’t the same thing as neural networks. […] distributed neural networks represent knowledge in a very different way. There, individual concepts are represented not by a single node in a carefully defined associative net, but by the changing patterns of activity across an entire network. Such systems can tolerate conflicting evidence, so aren’t bedevilled by the problems of maintaining logical consistency […] Even a single mind involves distributed cognition, for it integrates many cognitive, motivational, and emotional subsystems […] Clearly, human-level AGI would involve distributed cognition.”
“In short, most human visual achievements surpass today’s AI. Often, AI researchers aren’t clear about what questions to ask. For instance, think about folding a slippery satin dress neatly. No robot can do this (although some can be instructed, step by step, how to fold an oblong terry towel). Or consider putting on a T-shirt: the head must go in first, and not via a sleeve — but why? Such topological problems hardly feature in AI. None of this implies that human-level computer vision is impossible. But achieving it is much more difficult than most people believe. So this is a special case of the fact noted in Chapter 1: that AI has taught us that human minds are hugely richer, and more subtle, than psychologists previously imagined. Indeed, that is the main lesson to be learned from AI. […] Difficult though it is to build a high-performing AI specialist, building an AI generalist is orders of magnitude harder. (Deep learning isn’t the answer: its aficionados admit that ‘new paradigms are needed’ to combine it with complex reasoning — scholarly code for ‘we haven’t got a clue’.) That’s why most AI researchers abandoned that early hope, turning instead to multifarious narrowly defined tasks—often with spectacular success.”
“Some machine learning uses neural networks. But much relies on symbolic AI, supplemented by powerful statistical algorithms. In fact, the statistics really do the work, the GOFAI merely guiding the worker to the workplace. Accordingly, some professionals regard machine learning as computer science and/or statistics —not AI. However, there’s no clear boundary here. Machine learning has three broad types: supervised, unsupervised, and reinforcement learning. […] In supervised learning, the programmer ‘trains’ the system by defining a set of desired outcomes for a range of inputs […], and providing continual feedback about whether it has achieved them. The learning system generates hypotheses about the relevant features. Whenever it classifies incorrectly, it amends its hypothesis accordingly. […] In unsupervised learning, the user provides no desired outcomes or error messages. Learning is driven by the principle that co-occurring features engender expectations that they will co-occur in future. Unsupervised learning can be used to discover knowledge. The programmers needn’t know what patterns/clusters exist in the data: the system finds them for itself […but even though Boden does not mention this fact, caution is most definitely warranted when applying such systems/methods to data (..it remains true that “Truth and true models are not statistically identifiable from data” – as usual, the go-to reference here is Burnham & Anderson)]. Finally, reinforcement learning is driven by analogues of reward and punishment: feedback messages telling the system that what it just did was good or bad. Often, reinforcement isn’t simply binary […] Given various theories of probability, there are many different algorithms suitable for distinct types of learning and different data sets.”
“Countless AI applications use natural language processing (NLP). Most focus on the computer’s ‘understanding’ of language that is presented to it, not on its own linguistic production. That’s because NLP generation is even more difficult than NLP acceptance [I had a suspicion this might be the case before reading the book, but I didn’t know – US]. […] It’s now clear that handling fancy syntax isn’t necessary for summarizing, questioning, or translating a natural-language text. Today’s NLP relies more on brawn (computational power) than on brain (grammatical analysis). Mathematics — specifically, statistics — has overtaken logic, and machine learning (including, but not restricted to, deep learning) has displaced syntactic analysis. […] In modern-day NLP, powerful computers do statistical searches of huge collections (‘corpora’) of texts […] to find word patterns both commonplace and unexpected. […] In general […], the focus is on words and phrases, not syntax. […] Machine-matching of languages from different language groups is usually difficult. […] Human judgements of relevance are often […] much too subtle for today’s NLP. Indeed, relevance is a linguistic/conceptual version of the unforgiving ‘frame problem‘ in robotics […]. Many people would argue that it will never be wholly mastered by a non-human system.”
“[M]any AI research groups are now addressing emotion. Most (not quite all) of this research is theoretically shallow. And most is potentially lucrative, being aimed at developing ‘computer companions’. These are AI systems — some screen-based, some ambulatory robots — designed to interact with people in ways that (besides being practically helpful) are affectively comfortable, even satisfying, for the user. Most are aimed at the elderly and/or disabled, including people with incipient dementia. Some are targeted on babies or infants. Others are interactive ‘adult toys’. […] AI systems can already recognize human emotions in various ways. Some are physiological: monitoring the person’s breathing rate and galvanic skin response. Some are verbal: noting the speaker’s speed and intonation, as well as their vocabulary. And some are visual: analysing their facial expressions. At present, all these methods are relatively crude. The user’s emotions are both easily missed and easily misinterpreted. […] [An] point [point], here [in the development and evaluation of AI], is that emotions aren’t merely feelings. They involve functional, as well as phenomenal, consciousness […]. Specifically, they are computational mechanisms that enable us to schedule competing motives – and without which we couldn’t function. […] If we are ever to achieve AGI, emotions such as anxiety will have to be included – and used.”
[The point made in the book is better made in Aureli et al.‘s book, especially the last chapters to which the coverage in the linked post refer. The point is that emotions enable us to make better decisions, or perhaps even to make a decision in the first place; the emotions we feel in specific contexts will tend not to be even remotely random, rather they will tend to a significant extent to be Nature’s (…and Mr. Darwin’s) attempt to tell us how to handle a specific conflict of interest in the ‘best’ manner. You don’t need to do the math, your forebears did it for you, which is why you’re now …angry, worried, anxious, etc. If you had to do the math every time before you made a decision, you’d be in trouble, and emotions provide a great shortcut in many contexts. The potential for such short-cuts seems really important if you want an agent to act intelligently, regardless of whether said agent is ‘artificial’ or not. The book very briefly mentions a few of Minsky’s thoughts on these topics, and people who are curious could probably do worse than read some of his stuff. This book seems like a place to start.]
…
Links:
GOFAI (“Good Old-Fashioned Artificial Intelligence”).
Ada Lovelace. Charles Babbage. Alan Turing. Turing machine. Turing test. Norbert Wiener. John von Neumann. W. Ross Ashby. William Grey Walter. Oliver Selfridge. Kenneth Craik. Gregory Bateson. Frank Rosenblatt. Marvin Minsky. Seymour Papert.
A logical calculus of the ideas immanent in nervous activity (McCulloch & Pitts, 1943).
Propositional logic. Logic gate.
Arthur Samuel’s checkers player. Logic Theorist. General Problem Solver. The Homeostat. Pandemonium architecture. Perceptron. Cyc.
Fault-tolerant computer system.
Cybernetics.
Programmed Data Processor (PDP).
Artificial life.
Forward chaining. Backward chaining.
Rule-based programming. MYCIN. Dendral.
Semantic network.
Non-monotonic logic. Fuzzy logic.
Facial recognition system. Computer vision.
Bayesian statistics.
Helmholtz machine.
DQN algorithm.
AlphaGo. AlphaZero.
Human Problem Solving (Newell & Simon, 1970).
ACT-R.
NELL (Never-Ending Language Learning).
SHRDLU.
ALPAC.
Google translate.
Data mining. Sentiment analysis. Siri. Watson (computer).
Paro (robot).
Uncanny valley.
CogAff architecture.
Connectionism.
Constraint satisfaction.
Content-addressable memory.
Graceful degradation.
Physical symbol system hypothesis.
Principles of memory (III)
I have added a few observations from the last part of the book below. This is a short post, but I was getting tired of the lack of (front-page) updates – I do apologize to the (…fortunately very-) few people who might care about this for the infrequent updates lately, I hope to have more energy for blogging in the weeks to come.
…
“The relative distinctiveness principle states that performance on memory tasks depends on how much an item stands out “relative to the background of alternatives from which it must be distinguished” at the time of retrieval […]. It is important to keep in mind that one of the determinants of whether an item is more or less distinct at the time of retrieval, relative to other items, is the relation between the conditions at encoding and those at retrieval (the encoding retrieval principle). […] There has been a long history of distinctiveness as an important concept and research topic in memory, with numerous early studies examining both “distinctiveness” and “vividness” […]. Perhaps the most well-known example of distinctiveness is the isolation or von Restorff effect […] In the typical isolation experiment, thereare two types of lists. The control list features words presented (for example) in black against a white background. The experimental list is identical to the control list in all respects except that one of the items is made to stand out in some fashion: it could be shown in green instead of black, in a larger font size, with a large red frame around it, the word trout could appear in a list in which all the other items are names of different vegetables, or any number of similar manipulations. The much-replicated result is that the unique item (the isolate) is remembered better than the item in the same position in the control list. […] The von Restorff effect is reliably obtained with many kinds of tests, including delayed free recall, serial recall, serial learning, recognition, and many others. It is also readily observable with nonverbal stimuli”.
“There have been many mathematical and computational models based on the idea of distinctiveness (see Neath & Brown, 2007, for a review). Here, we focus on one particular model that includes elements from many of the earlier models […]. Brown, Neath, and Chater (2007 […]) [Here’s a link to the paper, US] proposed a model called SIMPLE, which stands for Scale Independent Memory and Perceptual Learning. The model is scale independent in the sense that it applies equally to short-term/working memory as long-term memory: the time scale is irrelevant to the operation of the model. The basic idea is that memory is best conceived as a discrimination task. Items are represented as occupying positions along one or more dimensions and, in general, those items with fewer close neighbors on the relevant dimensions at the time of retrieval will be more likely to be recalled that items with more close neighbors. […] According to SIMPLE, […] not only is the isolation effect due to relative distinctiveness, but the general shape of the serial position curve is due to relative distinctiveness. In general, free and serial recall produce a function in which the first few items are well-recalled (the primacy effect) and the last few items are well recalled (the recency effect), but items in the middle are recalled less well. The magnitude of primacy and recency effects can be affected by many different manipulations, and depending on the experimental design, one can observe almost all possibilities, from almost all primacy to almost all recency. The thing that all have in common, however, is that the experimental manipulation has caused some items to be more distinct at the time of retrieval than other items. […] It has been claimed that distinctiveness effects are observed only in explicit memory […] We suggest that the search for distinctiveness effects in implicit memory tasks is similar to the search for interference in implicit memory tasks […]: What is important is whether the information that is supposed to be distinct (in the former case) or interfere (in the latter) is relevant to the task. If it is not relevant, then the effects will not be seen.”
“[O]lder adults perform worse than younger adults on free recall but not on recognition (Craik & McDowd, 1987), even though both tasks are considered to tap “episodic” or “explicit” memory.2 Performance on another episodic memory task, cued recall, falls in between recall and recognition, although the size of the age-related difference varies […]. Older adults also experience more tip-of-the-tongue events than younger adults […] and have more word-finding difficulties in confrontation naming tasks in which, for example, a drawing is shown and the subject is asked to name the object […]. [I]tem recall is not as affected by aging as order recall […] in comparison to younger adults, older adults have more difficulty remembering the source of a memory […] In addition to recalling fewer correct items than younger adults (errors of omission), older adults are also more likely than younger adults to produce false positive responses in a variety of paradigms (errors of commission) […] Similarly, older adults are more likely than younger to report that an imagined event was real […] Due perhaps to reduced cognitive capacity older adults may appear to encode fewer specific details at encoding and thus are less able to take advantage of specific cues at retrieval. […] older adults and individuals with amnesia perform quite well on tasks that are supported by generic processing but less well (compared to younger adults) on those that require the recollection of a specific item or event. […] when older adults are asked to recall events from their own lives, they recall more from the period when they were approximately 15 to 25 years of age than they do from the period when they were approximately 30 to 40 years of age.” [Here’s incidentally an example paper exploring some of these topics in more detail: Modeling age-related differences in immediate memory using SIMPLE. As should be obvious from the title, the paper relates to the SIMPLE model discussed in the previous paragraph, US]
“There is a large literature on the relation between attention and memory, and many times “memory” is used when a perhaps more accurate term is “attention” (see, for example, Baddeley, 1993; Cowan, 1995). […] As yet, we have no principles linking memory and attention.”
“Forgetting is due to extrinsic factors; in particular, items that have more close neighbors in the region of psychological space at the time of retrieval are less likely to be remembered than items with fewer close neighbors […]. In addition, tasks that require specific information about the context in which memories were formed seem to be more vulnerable to interference or forgetting at the time of the retrieval attempt than those that can rely on more general information […]. Taken together, these principles suggest that the search for the forgetting function is not likely to be successful. […] a failure to remember can be due to multiple different causes, much like the failure of a car can be due to multiple different causes.” (Do here also keep in mind the comments included on this topic in the last paragraph of my first post about the book, US)
Perception (I)
Here’s my short goodreads review of the book. In this post I’ll include some observations and links related to the first half of the book’s coverage.
…
“Since the 1960s, there have been many attempts to model the perceptual processes using computer algorithms, and the most influential figure of the last forty years has been David Marr, working at MIT. […] Marr and his colleagues were responsible for developing detailed algorithms for extracting (i) low-level information about the location of contours in the visual image, (ii) the motion of those contours, and (iii) the 3-D structure of objects in the world from binocular disparities and optic flow. In addition, one of his lasting achievements was to encourage researchers to be more rigorous in the way that perceptual tasks are described, analysed, and formulated and to use computer models to test the predictions of those models against human performance. […] Over the past fifteen years, many researchers in the field of perception have characterized perception as a Bayesian process […] According to Bayesian theory, what we perceive is a consequence of probabilistic processes that depend on the likelihood of certain events occurring in the particular world we live in. Moreover, most Bayesian models of perceptual processes assume that there is noise in the sensory signals and the amount of noise affects the reliability of those signals – the more noise, the less reliable the signal. Over the past fifteen years, Bayes theory has been used extensively to model the interaction between different discrepant cues, such as binocular disparity and texture gradients to specify the slant of an inclined surface.”
“All surfaces have the property of reflectance — that is, the extent to which they reflect (rather than absorb) the incident illumination — and those reflectances can vary between 0 per cent and 100 per cent. Surfaces can also be selective in the particular wavelengths they reflect or absorb. Our colour vision depends on these selective reflectance properties […]. Reflectance characteristics describe the physical properties of surfaces. The lightness of a surface refers to a perceptual judgement of a surface’s reflectance characteristic — whether it appears as black or white or some grey level in between. Note that we are talking about the perception of lightness — rather than brightness — which refers to our estimate of how much light is coming from a particular surface or is emitted by a source of illumination. The perception of surface lightness is one of the most fundamental perceptual abilities because it allows us not only to differentiate one surface from another but also to identify the real-world properties of a particular surface. Many textbooks start with the observation that lightness perception is a difficult task because the amount of light reflected from a particular surface depends on both the reflectance characteristic of the surface and the intensity of the incident illumination. For example, a piece of black paper under high illumination will reflect back more light to the eye than a piece of white paper under dim illumination. As a consequence, lightness constancy — the ability to correctly judge the lightness of a surface under different illumination conditions — is often considered to be an ‘achievement’ of the perceptual system. […] The alternative starting point for understanding lightness perception is to ask whether there is something that remains constant or invariant in the patterns of light reaching the eye with changes of illumination. In this case, it is the relative amount of light reflected off different surfaces. Consider two surfaces that have different reflectances—two shades of grey. The actual amount of light reflected off each of the surfaces will vary with changes in the illumination but the relative amount of light reflected off the two surfaces remains the same. This shows that lightness perception is necessarily a spatial task and hence a task that cannot be solved by considering one particular surface alone. Note that the relative amount of light reflected off different surfaces does not tell us about the absolute lightnesses of different surfaces—only their relative lightnesses […] Can our perception of lightness be fooled? Yes, of course it can and the ways in which we make mistakes in our perception of the lightnesses of surfaces can tell us much about the characteristics of the underlying processes.”
“From a survival point of view, the ability to differentiate objects and surfaces in the world by their ‘colours’ (spectral reflectance characteristics) can be extremely useful […] Most species of mammals, birds, fish, and insects possess several different types of receptor, each of which has a a different spectral sensitivity function […] having two types of receptor with different spectral sensitivities is the minimum necessary for colour vision. This is referred to as dicromacy and the majority of mammals are dichromats with the exception of the old world monkeys and humans. […] The only difference between lightness and colour perception is that in the latter case we have to consider the way a surface selectively reflects (and absorbs) different wavelengths, rather than just a surface’s average reflectance over all wavelengths. […] The similarities between the tasks of extracting lightness and colour information mean that we can ask a similar question about colour perception [as we did about lightness perception] – what is the invariant information that could specify the reflectance characteristic of a surface? […] The information that is invariant under changes of spectral illumination is the relative amounts of long, medium, and short wavelength light reaching our eyes from different surfaces in the scene. […] the successful identification and discrimination of coloured surfaces is dependent on making spatial comparisons between the amounts of short, medium, and long wavelength light reaching our eyes from different surfaces. As with lightness perception, colour perception is necessarily a spatial task. It follows that if a scene is illuminated by the light of just a single wavelength, the appropriate spatial comparisons cannot be made. This can be demonstrated by illuminating a real-world scene containing many different coloured objects with yellow, sodium light that contains only a single wavelength. All objects, whatever their ‘colours’, will only reflect back to the eye different intensities of that sodium light and hence there will only be absolute but no relative differences between the short, medium, and long wavelength lightness records. There is a similar, but less dramatic, effect on our perception of colour when the spectral characteristics of the illumination are restricted to just a few wavelengths, as is the case with fluorescent lighting.”
“Consider a single receptor mechanism, such as a rod receptor in the human visual system, that responds to a limited range of wavelengths—referred to as the receptor’s spectral sensitivity function […]. This hypothetical receptor is more sensitive to some wavelengths (around 550 nm) than others and we might be tempted to think that a single type of receptor could provide information about the wavelength of the light reaching the receptor. This is not the case, however, because an increase or decrease in the response of that receptor could be due to either a change in the wavelength or an increase or decrease in the amount of light reaching the receptor. In other words, the output of a given receptor or receptor type perfectly confounds changes in wavelength with changes in intensity because it has only one way of responding — that is, more or less. This is Rushton’s Principle of Univariance — there is only one way of varying or one degree of freedom. […] On the other hand, if we consider a visual system with two different receptor types, one more sensitive to longer wavelengths (L) and the other more sensitive to shorter wavelengths (S), there are two degrees of freedom in the system and thus the possibility of signalling our two independent variables — wavelength and intensity […] it is quite possible to have a colour visual system that is based on just two receptor types. Such a colour visual system is referred to as dichromatic.”
“So why is the human visual system trichromatic? The answer can be found in a phenomenon known as metamerism. So far, we have restricted our discussion to the effect of a single wavelength on our dichromatic visual system: for example, a single wavelength of around 550 nm that stimulated both the long and short receptor types about equally […]. But what would happen if we stimulated our dichromatic system with light of two different wavelengths at the same time — one long wavelength and one short wavelength? With a suitable choice of wavelengths, this combination of wavelengths would also have the effect of stimulating the two receptor types about equally […] As a consequence, the output of the system […] with this particular mixture of wavelengths would be indistinguishable from that created by the single wavelength of 550 nm. These two indistinguishable stimulus situations are referred to as metamers and a little thought shows that there would be many thousands of combinations of wavelength that produce the same activity […] in a dichromatic visual system. As a consequence, all these different combinations of wavelengths would be indistinguishable to a dichromatic observer, even though they were produced by very different combinations of wavelengths. […] Is there any way of avoiding the problem of metamerism? The answer is no but we can make things better. If a visual system had three receptor types rather than two, then many of the combinations of wavelengths that produce an identical pattern of activity in two of the mechanisms (L and S) would create a different amount of activity in our third receptor type (M) that is maximally sensitive to medium wavelengths. Hence the number of indistinguishable metameric matches would be significantly reduced but they would never be eliminated. Using the same logic, it follows that a further increase in the number of receptor types (beyond three) would reduce the problem of metamerism even more […]. There would, however, also be a cost. Having more distinct receptor types in a finite-sized retina would increase the average spacing between the receptors of the same type and thus make our acuity for fine detail significantly poorer. There are many species, such as dragonflies, with more than three receptor types in their eyes but the larger number of receptor types typically serves to increase the range of wavelengths to which the animal is sensitive into the infra-red or ultra-violet parts of the spectrum, rather than to reduce the number of metamers. […] the sensitivity of the short wavelength receptors in the human eye only extends to ~540 nm — the S receptors are insensitive to longer wavelengths. This means that human colour vision is effectively dichromatic for combinations of wavelengths above 540 nm. In addition, there are no short wavelength cones in the central fovea of the human retina, which means that we are also dichromatic in the central part of our visual field. The fact that we are unaware of this lack of colour vision is probably due to the fact that our eyes are constantly moving. […] It is […] important to appreciate that the description of the human colour visual system as trichromatic is not a description of the number of different receptor types in the retina – it is a property of the whole visual system.”
“Recent research has shown that although the majority of humans are trichromatic there can be significant differences in the precise matches that individuals make when matching colour patches […] the absence of one receptor type will result in a greater number of colour confusions than normal and this does have a significant effect on an observer’s colour vision. Protanopia is the absence of long wavelength receptors, deuteranopia the absence of medium wavelength receptors, and tritanopia the absence of short wavelength receptors. These three conditions are often described as ‘colour blindness’ but this is a misnomer. We are all colour blind to some extent because we all suffer from colour metamerism and fail to make discriminations that would be very apparent to any biological or machine vision system with a greater number of receptor types. For example, most stomatopod crustaceans (mantis shrimps) have twelve different visual pigments and they also have the ability to detect both linear and circularly polarized light. What I find interesting is that we believe, as trichromats, that we have the ability to discriminate all the possible shades of colour (reflectance characteristics) that exist in our world. […] we are typically unaware of the limitations of our visual systems because we have no way of comparing what we see normally with what would be seen by a ‘better’ visual system.”
“We take it for granted that we are able to segregate the visual input into separate objects and distinguish objects from their backgrounds and we rarely make mistakes except under impoverished conditions. How is this possible? In many cases, the boundaries of objects are defined by changes of luminance and colour and these changes allow us to separate or segregate an object from its background. But luminance and colour changes are also present in the textured surfaces of many objects and therefore we need to ask how it is that our visual system does not mistake these luminance and colour changes for the boundaries of objects. One answer is that object boundaries have special characteristics. In our world, most objects and surfaces are opaque and hence they occlude (cover) the surface of the background. As a consequence, the contours of the background surface typically end—they are ‘terminated’—at the boundary of the occluding object or surface. Quite often, the occluded contours of the background are also revealed at the opposite side of the occluding surface because they are physically continuous. […] The impression of occlusion is enhanced if the occluded contours contain a range of different lengths, widths, and orientations. In the natural world, many animals use colour and texture to camouflage their boundaries as well as to fool potential predators about their identity. […] There is an additional source of information — relative motion — that can be used to segregate a visual scene into objects and their backgrounds and to break any camouflage that might exist in a static view. A moving, opaque object will progressively occlude and dis-occlude (reveal) the background surface so that even a well-camouflaged, moving animal will give away its location. Hence it is not surprising that a very common and successful strategy of many animals is to freeze in order not to be seen. Unless the predator has a sophisticated visual system to break the pattern or colour camouflage, the prey will remain invisible.”
…
Some links:
Perception.
Ames room. Inverse problem in optics.
Hermann von Helmholtz. Richard Gregory. Irvin Rock. James Gibson. David Marr. Ewald Hering.
Optical flow.
La dioptrique.
Necker cube. Rubin’s vase.
Perceptual constancy. Texture gradient.
Ambient optic array.
Affordance.
Luminance.
Checker shadow illusion.
Shape from shading/Photometric stereo.
Colour vision. Colour constancy. Retinex model.
Cognitive neuroscience of visual object recognition.
Motion perception.
Horace Barlow. Bernhard Hassenstein. Werner E. Reichardt. Sigmund Exner. Jan Evangelista Purkyně.
Phi phenomenon.
Motion aftereffect.
Induced motion.
Principles of memory (II)
I have added a few more quotes from the book below:
…
“Watkins and Watkins (1975, p. 443) noted that cue overload is “emerging as a general principle of memory” and defined it as follows: “The efficiency of a functional retrieval cue in effecting recall of an item declines as the number of items it subsumes increases.” As an analogy, think of a person’s name as a cue. If you know only one person named Katherine, the name by itself is an excellent cue when asked how Katherine is doing. However, if you also know Cathryn, Catherine, and Kathryn, then it is less useful in specifying which person is the focus of the question. More formally, a number of studies have shown experimentally that memory performance systematically decreases as the number of items associated with a particular retrieval cue increases […] In many situations, a decrease in memory performance can be attributed to cue overload. This may not be the ultimate explanation, as cue overload itself needs an explanation, but it does serve to link a variety of otherwise disparate findings together.”
“Memory, like all other cognitive processes, is inherently constructive. Information from encoding and cues from retrieval, as well as generic information, are all exploited to construct a response to a cue. Work in several areas has long established that people will use whatever information is available to help reconstruct or build up a coherent memory of a story or an event […]. However, although these strategies can lead to successful and accurate remembering in some circumstances, the same processes can lead to distortion or even confabulation in others […]. There are a great many studies demonstrating the constructive and reconstructive nature of memory, and the literature is quite well known. […] it is clear that recall of events is deeply influenced by a tendency to reconstruct them using whatever information is relevant and to repair holes or fill in the gaps that are present in memory with likely substitutes. […] Given that memory is a reconstructive process, it should not be surprising to find that there is a large literature showing that people have difficulty distinguishing between memories of events that happened and memories of events that did not happen […]. In a typical reality monitoring experiment […], subjects are shown pictures of common objects. Every so often, instead of a picture, the subjects are shown the name of an object and are asked to create a mental image of the object. The test involves presenting a list of object names, and the subject is asked to judge whether they saw the item (i.e., judge the memory as “real”) or whether they saw the name of the object and only imagined seeing it (i.e., judge the memory as “imagined”). People are more likely to judge imagined events as real than real events as imagined. The likelihood that a memory will be judged as real rather than imagined depends upon the vividness of the memory in terms of its sensory quality, detail, plausibility, and coherence […]. What this means is that there is not a firm line between memories for real and imagined events: if an imagined event has enough qualitative features of a real event it is likely to be judged as real.”
“One hallmark of reconstructive processes is that in many circumstances they aid in memory retrieval because they rely on regularities in the world. If we know what usually happens in a given circumstance, we can use that information to fill in gaps that may be present in our memory for that episode. This will lead to a facilitation effect in some cases but will lead to errors in cases in which the most probable response is not the correct one. However, if we take this standpoint, we must predict that the errors that are made when using reconstructive processes will not be random; in fact, they will display a bias toward the most likely event. This sort of mechanism has been demonstrated many times in studies of schema-based representations […], and language production errors […] but less so in immediate recall. […] Each time an event is recalled, the memory is slightly different. Because of the interaction between encoding and retrieval, and because of the variations that occur between two different retrieval attempts, the resulting memories will always differ, even if only slightly.”
“In this chapter we discuss the idea that a task or a process can be a “pure” measure of memory, without contamination from other hypothetical memory stores or structures, and without contributions from other processes. Our impurity principle states that tasks and processes are not pure, and therefore one cannot separate out the contributions of different memory stores by using tasks thought to tap only one system; one cannot count on subjects using only one process for a particular task […]. Our principle follows from previous arguments articulated by Kolers and Roediger (1984) and Crowder (1993), among others, that because every event recruits slightly different encoding and retrieval processes, there is no such thing as “pure” memory. […] The fundamental issue is the extent to which one can determine the contribution of a particular memory system or structure or process to performance on a particular memory task. There are numerous ways of assessing memory, and many different ways of classifying tasks. […] For example, if you are given a word fragment and asked to complete it with the first word that pops in your head, you are free to try a variety of strategies. […] Very different types of processing can be used by subjects even when given the same type of test or cue. People will use any and all processes to help them answer a question.”
“A free recall test typically provides little environmental support. A list of items is presented, and the subject is asked to recall which items were on the list. […] The experimenter simply says, “Recall the words that were on the list,” […] A typical recognition test provides more environmental support. Although a comparable list of items might have been presented, and although the subject is asked again about memory for an item in context, the subject is provided with a more specific cue, and knows exactly how many items to respond to. Some tests, such as word fragment completion and general knowledge questions, offer more environmental support. These tests provide more targeted cues, and often the cues are unique […] One common processing distinction involves the aspects of the stimulus that are focused on or are salient at encoding and retrieval: Subjects can focus more on an item’s physical appearance (data driven processing) or on an item’s meaning (conceptually driven processing […]). In general, performance on tasks such as free recall that offer little environmental support is better if the rememberer uses conceptual rather than perceptual processing at encoding. Although there is perceptual information available at encoding, there is no perceptual information provided at test so data-driven processes tend not to be appropriate. Typical recognition and cued-recall tests provide more specific cues, and as such, data-driven processing becomes more appropriate, but these tasks still require the subject to discriminate which items were presented in a particular specific context; this is often better accomplished using conceptually driven processing. […] In addition to distinctions between data driven and conceptually driven processing, another common distinction is between an automatic retrieval process, which is usually referred to as familiarity, and a nonautomatic process, usually called recollection […]. Additional distinctions abound. Our point is that very different types of processing can be used by subjects on a particular task, and that tasks can differ from one another on a variety of different dimensions. In short, people can potentially use almost any combination of processes on any particular task.”
“Immediate serial recall is basically synonymous with memory span. In one the first reviews of this topic, Blankenship (1938, p. 2) noted that “memory span refers to the ability of an individual to reproduce immediately, after one presentation, a series of discrete stimuli in their original order.”3 The primary use of memory span was not so much to measure the capacity of a short-term memory system, but rather as a measure of intellectual abilities […]. Early on, however, it was recognized that memory span, whatever it was, varied as function of a large number of variables […], and could even be increased substantially by practice […]. Nonetheless, memory span became increasingly seen as a measure of the capacity of a short-term memory system that was distinct from long-term memory. Generally, most individuals can recall about 7 ± 2 items (Miller, 1956) or the number of items that can be pronounced in about 2 s (Baddeley, 1986) without making any mistakes. Does immediate serial recall (or memory span) measure the capacity of short-term (or working) memory? The currently available evidence suggests that it does not. […] The main difficulty in attempting to construct a “pure” measure of immediate memory capacity is that […] the influence of previously acquired knowledge is impossible to avoid. There are numerous contributions of long-term knowledge not only to memory span and immediate serial recall […] but to other short-term tasks as well […] Our impurity principle predicts that when distinctions are made between types of processing (e.g., conceptually driven versus data driven; familiarity versus recollection; automatic versus conceptual; item specific versus relational), each of those individual processes will not be pure measures of memory.”
“Over the past 20 years great strides have been made in noninvasive techniques for measuring brain activity. In particular, PET and fMRI studies have allowed us to obtain an on-line glimpse into the hemodynamic changes that occur in the brain as stimuli are being processed, memorized, manipulated, and recalled. However, many of these studies rely on subtractive logic that explicitly assumes that (a) there are different brain areas (structures) subserving different cognitive processes and (b) we can subtract out background or baseline activity and determine which areas are responsible for performing a particular task (or process) by itself. There have been some serious challenges to these underlying assumptions […]. A basic assumption is that there is some baseline activation that is present all of the time and that the baseline is built upon by adding more activation. Thus, when the baseline is subtracted out, what is left is a relatively pure measure of the brain areas that are active in completing the higher-level task. One assumption of this method is that adding a second component to the task does not affect the simple task. However, this assumption does not always hold true. […] Even if the additive factors logic were correct, these studies often assume that a task is a pure measure of one process or another. […] Again, the point is that humans will utilize whatever resources they can recruit in order to perform a task. Individuals using different retrieval strategies (e.g., visualization, verbalization, lax or strict decision criteria, etc.) show very different patterns of brain activation even when performing the same memory task (Miller & Van Horn, 2007). This makes it extremely dangerous to assume that any task is made up of purely one process. Even though many researchers involved in neuroimaging do not make task purity assumptions, these examples “illustrate the widespread practice in functional neuroimaging of interpreting activations only in terms of the particular cognitive function being investigated (Cabeza et al., 2003, p. 390).” […] We do not mean to suggest that these studies have no value — they clearly do add to our knowledge of how cognitive functioning works — but, instead, would like to urge more caution in the interpretation of localization studies, which are sometimes taken as showing that an activated area is where some unique process takes place.”
Principles of memory (I)
This book was interesting, but it was more interesting to me on account of the fact that it’s telling you a lot about what sort of memory research has taken place over the years, than it was interesting on account of the authors having presented a good model of how this stuff works. It’s the sort of book that makes you think.
I found the book challenging to blog, for a variety of reasons, but I’ve tried adding some observations of interest from the first four chapters of the coverage below.
…
“[I]n over 100 years of scientific research on memory, and nearly 50 years after the so-called cognitive revolution, we have nothing that really constitutes a widely accepted and frequently cited law of memory, and perhaps only one generally accepted principle.5 However, there are a plethora of effects, many of which have extensive literatures and hundreds of published empirical demonstrations. One reason for the lack of general laws and principles of memory might be that none exists. Tulving (1985a, p. 385), for example, has argued that “no profound generalizations can be made about memory as a whole,”because memory comprises many different systems and each system operates according to different principles. One can make “general statements about particular kinds of memory,” but one cannot make statements that would apply to all types of memory. […] Roediger (2008) also argues that no general principles of memory exist, but his reasoning and arguments are quite different. He reintroduces Jenkins’ (1979) tetrahedral model of memory, which views all memory experiments as comprising four factors: encoding conditions, retrieval conditions, subject variables, and events (materials and tasks). Using the tetrahedral model as a starting point, Roediger convincingly demonstrates that all of these variables can affect memory performance in different ways and that such complexity does not easily lend itself to a description using general principles. Because of the complexity of the interactions among these variables, Roediger suggests that “the most fundamental principle of learning and memory, perhaps its only sort of general law, is that in making any generalization about memory one must add that ‘it depends'” (p. 247). […] Where we differ is that we think it possible to produce general principles of memory that take into account these factors. […] The purpose of this monograph is to propose seven principles of human memory that apply to all memory regardless of the type of information, type of processing, hypothetical system supporting memory, or time scale. Although these principles focus on the invariants and empirical regularities of memory, the reader should be forewarned that they are qualitative rather than quantitative, more like regularities in biology than principles of geometry. […] Few, if any, of our principles are novel, and the list is by no means complete. We certainly do not think that there are only seven principles of memory nor, when more principles are proposed, do we think that all seven of our principles will be among the most important.7″
“[T]he two most popular contemporary ways of looking at memory are the multiple systems view and the process (or proceduralist) view.1 Although these views are not always necessarily diametrically opposed […], their respective research programs are focused on different questions and search for different answers. The fundamental difference between structural and processing accounts of memory is whether different rules apply as a function of the way information is acquired, the type of material learned, and the time scale, or whether these can be explained using a single set of principles. […] Proponents of the systems view of memory suggest that memory is divided into multiple systems. Thus, their endeavor is focused on discovering and defining different systems and describing how they work. A “system” within this sort of framework is a structure that is anatomically and evolutionarily distinct from other memory systems and differs in its “methods of acquisition, representation and expression of knowledge” […] Using a variety of techniques, including neuropsychological and statistical methods, advocates of the multiple systems approach […] have identified five major memory systems: procedural memory, the perceptual representation system (PRS), semantic memory, primary or working memory, and episodic memory. […] In general, three criticisms are raised most often: The systems approach (a) has no criteria that produce exactly five different memory systems, (b) relies to a large extent on dissociations, and (c) has great difficulty accounting for the pattern of results observed at both ends of the life span. […] The multiple systems view […] lacks a principled and consistent set of criteria for delineating memory systems. Given the current state of affairs, it is not unthinkable to postulate 5 or 10 or 20 or even more different memory systems […]. Moreover, the specific memory systems that have been identified can be fractionated further, resulting in a situation in which the system is distributed in multiple brain locations, depending on the demands of the task at hand. […] The major strength of the systems view is usually taken to be its ability to account for data from amnesic patients […]. Those individuals seem to have specific deficits in episodic memory (recall and recognition) with very few, if any, deficits in semantic memory, procedural memory, or the PRS. […] [But on the other hand] age-related differences in memory do not follow the pattern predicted by the systems view.”
“From our point of view, asking where memory is “located” in the brain is like asking where running is located in the body. There are certainly parts of the body that are more important (the legs) or less important (the little fingers) in performing the task of running but, in the end, it is an activity that requires complex coordination among a great many body parts and muscle groups. To extend the analogy, looking for differences between memory systems is like looking for differences between running and walking. There certainly are many differences, but the main difference is that running requires more coordination among the different body parts and can be disrupted by small things (such as a corn on the toe) that may not interfere with walking at all. Are we to conclude, then, that running is located in the corn on your toe? […] although there is little doubt that more primitive functions such as low-level sensations can be organized in localized brain regions, it is likely that more complex cognitive functions, such as memory, are more accurately described by a dynamic coordination of distributed interconnected areas […]. This sort of approach implies that memory, per se, does not exist but, instead, “information … resides at the level of the large-scale network” (Bressler & Kelso, 2001, p. 33).”
“The processing view […] emphasizes encoding and retrieval processes instead of the system or location in which the memory might be stored. […] Processes, not structures, are what is fundamental. […] The major criticisms of the processing approaches parallel those that have been leveled at the systems view: (a) number of processes or components (instead of number of systems), (b) testability […], and (c) issues with a special population (amnesia rather than life span development). […] The major weakness of the processing view is the major strength of the systems view: patients diagnosed with amnesic syndrome. […] it is difficult to account for data showing a complete abolishment of episodic memory with no apparent effect on semantic memory, procedural memory, or the PRS without appealing to a separate memory store. […] We suggest that in the absence of a compelling reason to prefer the systems view over the processing view (or vice versa), it would be fruitful to consider memory from a functional perspective. We do not know how many memory systems there are or how to define what a memory system is. We do not know how many processes (or components of processing) there are or how to distinguish them. We do acknowledge that short-term memory and long-term memory seem to differ in some ways, as do episodic memory and semantic memory, but are they really fundamentally different? Both the systems approach and, to a lesser extent, the proceduralist approach emphasize differences. Our approach emphasizes similarities. We suggest that a search for general principles of memory, based on fundamental empirical regularities, can act as a spur to theory development and a reexamination of systems versus process theories of memory.”
“Our first principle states that all memory is cue driven; without a cue, there can be no memory […]. By cue we mean a specific prompt or query, such as “Did you see this word on the previous list?” […] cues can also be nonverbal, such as odors […], emotions […], nonverbal sounds […], and images […], to name only a few. Although in many situations the person is fully aware that the cue is part of a memory test, this need not be the case. […] Computer simulation models of memory acknowledge the importance of cues by building them into the system; indeed, computer simulation models will not work unless there is a cue. In general, some input is provided to these models, and then a response is provided. The so-called global models of memory, SAM, TODAM, and MINERVA2, are all cue driven. […] it is hard to conceive of a computer model of memory that is not cue dependent, simply because the computer requires something to start the retrieval process. […] There is near unanimity in the view that memory is cue driven. The one area in which this view is contested concerns a particular form of memory that is characterized by highly restrictive capacity limitations.”
“The most commonly cited principle of memory, according to [our] literature search […], is the encoding specificity principle […] Our version of this is called the encoding-retrieval principle [and] states that memory depends on the relation between the conditions at encoding and the conditions at retrieval. […] An appreciation for the importance of the encoding-retrieval interaction came about as the result of studies that examined the potency of various cues to elicit items from memory. A strong cue is a word that elicits a particular target word most of the time. For example, when most people hear the word bloom, the first word that pops into their head is often flower. A weak cue is a word that only rarely elicits a particular target. […] A reasonable prediction seems to be that strong cues should be better than weak cues for eliciting the correct item. However, this inference is not entirely correct because it fails to take into account the relationship between the encoding and retrieval conditions. […] the effectiveness of even a long-standing strong cue depends crucially on the processes that occurred at study and the cues available at test. This basic idea became the foundation of the transfer-appropriate processing framework. […] Taken literally, all that transfer-appropriate processing requires is that the processing done at encoding be appropriate given the processing that will be required at test; it permits processing that is identical and permits processing that is similar. It also, however, permits processing that is completely different as long as it is appropriate. […] many proponents of this view act as if the name were “transfer similar processing” and express the idea as requiring a “match” or “overlap” between study and test. […] However, just because increasing the match sometimes leads to enhanced retention does not mean that it is the match that is the critical variable. […] one can easily set up situations in which the degree of match is improved and memory retention is worse, or the degree of match is decreased and memory is better, or the degree of match is changed (either increased or decreased) and it has no effect on retention. Match, then, is simply not the critical variable in determining memory performance. […] The retrieval conditions include other possible responses, and these other items can affect performance. The most accurate description, then, is that it is the relation between encoding and retrieval that matters, not the degree of match or similarity. […] As Tulving (1983, p. 239) noted, the dynamic relation between encoding and retrieval conditions prohibits any statements that take the following forms:
1. “Items (events) of class X are easier to remember than items (events) of class Y.”
2. “Encoding operations of class X are more effective than encoding operations of class Y.”
3. “Retrieval cues of class X are more effective than retrieval cues of class Y.”
Absolute statements that do not specify both the encoding and the retrieval conditions are meaningless because an experimenter can easily
change some aspect of the encoding or retrieval conditions and greatly change the memory performance.”
“In most areas of memory research, forgetting is seen as due to retrieval failure, often ascribed to some form of interference. There are, however, two areas of memory research that propose that forgetting is due to an intrinsic property of the memory trace, namely, decay. […] The two most common accounts view decay as either a mathematical convenience in a model, in which a parameter t is associated with time and leads to worse performance, or as some loss of information, in which it is unclear exactly what aspect of memory is decaying and what parts remain. In principle, a decay theory of memory could be proposed that is specific and testable, such as a process analogous to radioactive decay, in which it is understood precisely what is lost and what remains. Thus far, no such decay theory exists. Decay is posited as the forgetting mechanism in only two areas of memory research, sensory memory and short-term/working memory. […] One reason that time-based forgetting, such as decay, is often invoked is the common belief that short-term/working memory is immune to interference, especially proactive interference […]. This is simply not so. […] interference effects are readily observed in the short term. […] Decay predicts the same decrease for the same duration of distractor activity. Interference predicts differential effects depending on the presence or absence of interfering items. Numerous studies support the interference predictions and disconfirm predictions made on the basis of a decay view […] You might be tempted to say, yes, well, there are occasions in which the passage of time is either uncorrelated with or even negatively correlated with memory performance, but on average, you do worse with longer retention intervals. However, this confirms that the putative principle — the memorability of an event declines as the length of the storage interval increases — is not correct. […] One can make statements about the effects of absolute time, but only to the extent that one specifies both the conditions at encoding and those at retrieval. […] It is trivially easy to construct an experiment in which memory for an item does not change or even gets better the longer the retention interval. Here, we provide only eight examples, although there are numerous other examples; a more complete review and discussion are offered by Capaldi and Neath (1995) and Bjork (2001).”
Personal Relationships… (III)
Some more observations from the book below:
…
“Early research on team processes […] noted that for teams to be effective members must minimize “process losses” and maximize “process gains” — that is, identify ways the team can collectively perform at a level that exceeds the average potential of individual members. To do so, teams need to minimize interpersonal disruptions and maximize interpersonal facilitation among its members […] the prevailing view — backed by empirical findings […] — is that positive social exchanges lead to positive outcomes in teams, whereas negative social exchanges lead to negative outcomes in teams. However, this view may be challenged, in that positive exchanges can sometime lead to negative outcomes, whereas negative exchanges may sometime lead to positive outcomes. For example, research on groupthink (Janis, 1972) suggests that highly cohesive groups can make suboptimal decisions. That is, cohesion […] can lead to suboptimal group performance. As another example, under certain circumstances, negative behavior (e.g., verbal attacks or sabotage directed at another member) by one person in the team could lead to a series of positive exchanges in the team. Such subsequent positive exchanges may involve stronger bonding among other members in support of the targeted member, enforcement of more positive and cordial behavioral norms among members, or resolution of possible conflict between members that might have led to this particular negative exchange.”
“[T]here is […] clear merit in considering social exchanges in teams from a social network perspective. Doing so requires the integration of dyadic-level processes with team-level processes. Specifically, to capture the extent to which certain forms of social exchange networks in teams are formed (e.g., friendship, instrumental, or rather adversary ties), researchers must first consider the dyadic exchanges or ties between all members in the team. Doing so can help researchers identify the extent to which certain forms of ties or other social exchanges are dense in the team […] An important question […] is whether the level of social exchange density in the team might moderate the effects of social exchanges, much like social exchanges strength might strengthen the effects of social exchanges […]. For example, might teams with denser social support networks be able to better handle negative social exchanges in the team when such exchanges emerge? […] the effects of differences in centrality and subgroupings or fault lines may vary, depending on certain factors. Specifically, being more central within the team’s network of social exchange may mean that the more central member receives more support from more members, or, rather, that the more central member is engaged in more negative social exchanges with more members. Likewise, subgroupings or fault lines in the team may lead to negative consequences when they are associated with lack of critical communication among members but not when they reflect the correct form of communication network […] social exchange constructs are likely to exert stronger influences on individual team members when exchanges are more highly shared (and reflected in more dense networks). By the same token, individuals are more likely to react to social exchanges in their team when exchanges are directed at them from more team members”.
“[C]ustomer relationship management (CRM) has garnered growing interest from both research and practice communities in marketing. The purpose of CRM is “to efficiently and effectively increase the acquisition and retention of profitable customers by selectively initiating, building and maintaining appropriate relationships with them” […] Research has shown that successfully implemented CRM programs result in positive outcomes. In a recent meta-analysis, Palmatier, Dant, Grewal, and Evans (2006) found that investments in relationship marketing have a large, direct effect on seller objective performance. In addition, there has been ample research demonstrating that the effects of relationship marketing on outcomes are mediated by relational constructs that include trust […] and commitment […]. Combining these individual predictors by examining the effects of the global construct of relationship quality is also predictive of positive firm performance […] Meta-analytic findings suggest that CRM is more effective when relationships are built with an individual person rather than a selling firm […] Gutek (1995) proposed a typology of service delivery relationships with customers: encounters, pseudo-relationships, and relationships. […] service encounters usually consist of a solitary interaction between a customer and a service employee, with the expectation that they will not interact in the future. […] in a service encounter, customers do not identify with either the individual service employee with whom they interact or with the service organization. […] An alternate to the service encounter relationship is the pseudorelationship, which arises when a customer interacts with different individual service employees but usually (if not always) from the same service organization […] in pseudo-relationships, the customer identifies with the service of a particular service organization, not with an individual service employee. Finally, personal service relationships emerge when customers have repeated interactions with the same individual service provider […] We argue that the nature of these different types of service relationships […] will influence the types and levels of resources exchanged between the customer and the employee during the service interaction, which may further affect customer and employee outcomes from the service interaction.”
“According to social exchange theory, individuals form relationships and engage in social interactions as a means of obtaining needed resources […]. Within a social exchange relationship, individuals may exchange a variety of resources, both tangible and intangible. In the study of exchange relationships, the content of the exchange, or what resources are being exchanged, is often used as an indicator of the quality of the relationship. On the one hand, the greater the quality of resources exchanged, the better the quality of the relationship; on the other hand, the better the relationship, the more likely these resources are exchanged. Therefore, it is important to understand the specific resources exchanged between the service provider and the customer […] Ferris and colleagues (2009) proposed that several elements of a relationship develop because of social exchange: trust, respect, affect, and support. In an interaction between a service provider and a customer, most of the resources that are exchanged are non-economic in nature […]. Examples include smiling, making eye contact, and speaking in a rhythmic (non-monotone) vocal tone […]. Through these gestures, the service provider and the customer may demonstrate a positive affect toward each other. In addition, greeting courteously, listening attentively to customers, and providing assistance to address customer needs may show the service provider’s respect and support to the customer; likewise, providing necessary information, clarifying their needs and expectations, cooperating with the service provider by following proper instructions, and showing gratitude to the service provider may indicate customers’ respect and support to the service provider. Further, through placing confidence in the fairness and honesty of the customer and accuracy of the information the customer provides, the service provider offers the customer his or her trust; similarly, through placing confidence in the expertise and good intentions of the service provider, the customer offers his or her trust in the service provider’s competence and integrity. Some of the resources exchanged, particularly special treatment, between a service provider and a customer are of both economic and social value. For example, the customer may receive special discounts or priority service, which not only offers the customer economic benefits but also shows how much the service provider values and supports the customer. Similarly, a service provider who receives an extra big tip from a customer is not only better off economically but also gains a sense of recognition and esteem. The more these social resources of trust, respect, affect, and support, as well as special treatment, are mutually exchanged in the provider–customer interactions, the higher the quality of the service interaction for both parties involved. […] we argue that the potential for the exchange of resources […] depends on the nature of the service relationship. In other words, the quantity and quality of resources exchanged in discrete service encounters, pseudo-relationships, and personal service relationships are distinct.”
“Though customer–employee exchanges can be highly rewarding for both parties, they can also “turn ugly,” […]. In fact, though negative interactions such as rudeness, verbal abuse, or harassment are rare, employees are more likely to report them from customers than from coworkers or supervisors […] customer–employee exchanges are more likely to involve negative treatment than exchanges with organizational insiders. […] Such negative exchanges result in emotional labor and employee burnout […], covert sabotage of services or goods, or, in atypical cases […] direct retaliation and withdrawal […] Employee–customer exchanges are characterized by a strong power differential […] customers can influence the employees’ desired resources, have more choice over whether to continue the relationship, and can act in negative ways with few consequences (Yagil, 2008) […] One common way to conceptualize the impact of negative customer–employee interactions is Hirschman’s (1970) Exit-Voice-loyalty model. Management can learn of customers’ dissatisfaction by their reduced loyalty, voice, or exit. […] Customers rarely, if ever, see themselves as the source of the problem; in contrast, employees are highly likely to see customers as the reason for a negative exchange […] when employees feel customers’ allocation of resources (e.g., tips, purchases) are not commensurate with the time or energy expended (i.e., distributive injustice) or interpersonal treatment of employees is unjustified or violates norms (i.e., interactional injustice), they feel anger and anxiety […] Given these strong emotional responses, emotional deviance is a possible outcome in the service exchange. Emotional deviance is when employees violate display rules by expressing their negative feelings […] To avoid emotional deviance, service providers engage in emotion regulation […]. In lab and field settings, perceived customer mistreatment is linked to “emotional labor,” specifically regulating emotions by faking or suppressing emotions […] Customer mistreatment — incivility as well as verbal abuse — is well linked to employee burnout, and this effect exists beyond other job stressors (e.g., time pressure, constraints) and beyond mistreatment from supervisors and coworkers”.
“Though a customer may complain or yell at an employee in hopes of improving service, most evidence suggests the opposite occurs. First, service providers tend to withdraw from negative or deviant customers (e.g., avoiding eye contact or going to the back room[)] […] Engaging in withdrawal or other counterproductive work behaviors (CWBs) in response to mistreatment can actually reduce burnout […], but the behavior is likely to create another dissatisfied customer or two in the meantime. Second, mistreatment can also result in the employees reduced task performance in the service exchange. Stressful work events redirect attention toward sense making, even when mistreatment is fairly ambiguous or mild […] and thus reduce cognitive performance […]. Regulating those negative emotions also requires attentional resources, and both surface and deep acting reduce memory recall compared with expressing felt emotions […] Moreover, the more that service providers feel exhausted and burned out, the less positive their interpersonal performance […] Finally, perceived incivility or aggressive treatment from customers, and the resulting job dissatisfaction, is a key predictor of intentional customer-directed deviant behavior or service sabotage […] Dissatisfied employees engage in less extra-effort behavior than satisfied employees […]. More insidious, they may engage in intentionally deviant performance that is likely to be covert […] and thus difficult to detect and manage […] Examples of service sabotage include intentionally giving the customer faulty or damaged goods, slowing down service pace, or making “mistakes” in the service transaction, all of which are then linked to lower service performance from the customers’ perspective […]. This creates a feedback loop from employee behaviors to customer perceptions […] Typical human resource practices can help service management […], and practices such as good selection and providing training should reduce the likelihood of service failures and the resulting negative reactions from customers […]. Support from colleagues can help buffer the reactions to customer-instigated mistreatment. Individual perceptions of social support moderate the strain from emotional labor […], and formal interventions increasing individual or unit-level social support reduce strain from emotionally demanding interactions with the public (Le Blanc, Hox, Schaufeli, & Taris, 2007).”
Personal Relationships… (II)
Some more observations from the book below:
…
“Coworker support, or the processes by which coworkers provide assistance with tasks, information, or empathy, has long been considered an important construct in the stress and strain literature […] Social support fits the conservation of resources theory definition of a resource, and it is commonly viewed in that light […]. Support from coworkers helps employees meet the demands of their job, thus making strain less likely […]. In a sense, social support is the currency upon which social exchanges are based. […] The personality of coworkers can play an important role in the development of positive coworker relationships. For example, there is ample evidence that suggests that those higher in conscientiousness and agreeableness are more likely to help coworkers […] Further, similarity in personality between coworkers (e.g., coworkers who are similar in their conscientiousness) draws coworkers together into closer relationships […] cross-sex relationships appear to be managed in a different manner than same-sex relationships. […] members of cross-sex friendships fear the misinterpretation of their relationship by those outside the relationship as a sexual relationship rather than platonic […] a key goal of partners in a cross-sex workplace friendship becomes convincing “third parties that the friendship is authentic.” As a result, cross-sex workplace friends will intentionally limit the intimacy of their communication or limit their non-work-related communication to situations perceived to demonstrate a nonsexual relationship, such as socializing with a cross-sex friend only in the presence of his or her spouse […] demographic dissimilarity in age and race can reduce the likelihood of positive coworker relationships. Chattopadhyay (1999) found that greater dissimilarity among group members on age and race were associated with less collegial relationships among coworkers, which was subsequently associated with less altruistic behavior […] Sias and Cahill (1998) found that a variety of situational characteristics, both inside and outside the workplace setting, helps to predict the development of workplace friendship. For example, they found that factors outside the workplace, such as shared outside interests (e.g., similar hobbies), life events (e.g., having a child), and the simple passing of time can lead to a greater likelihood of a friendship developing. Moreover, internal workplace characteristics, including working together on tasks, physical proximity within the office, a common problem or enemy, and significant amounts of “downtime” that allow for greater socialization, also support friendship development in the workplace (see also Fine, 1986).”
“To build knowledge, employees need to be willing to learn and try new things. Positive relationships are associated with a higher willingness to engage in learning and experimentation […] and, importantly, sharing of that new knowledge to benefit others […] Knowledge sharing is dependent on high-quality communication between relational partners […] Positive relationships are characterized by less defensive communication when relational partners provide feedback (e.g., a suggestion for a better way to accomplish a task; Roberts, 2007). In a coworker context, this would involve accepting help from coworkers without putting up barriers to that help (e.g., nonverbal cues that the help is not appreciated or welcome). […] A recent meta-analysis by Chiaburu and Harrison (2008) found that coworker support was associated with higher performance and higher organizational citizenship behavior (both directed at individuals and directed at the organization broadly). These relationships held whether performance was self- or supervisor related […] Chiaburu and Harrison (2008) also found that coworker support was associated with higher satisfaction and organizational commitment […] Positive coworker exchanges are also associated with lower levels of employee withdrawal, including absenteeism, intention to turnover, and actual turnover […]. To some extent, these relationships may result from norms within the workplace, as coworkers help to set standards for behavior and not “being there” for other coworkers, particularly in situations where the work is highly interdependent, may be considered a significant violation of social norms within a positive working environment […] Perhaps not surprisingly, given the proximity and the amount of time spent with coworkers, workplace friendships will occasionally develop into romances and, potentially, marriages. While still small, the literature on married coworkers suggests that they experience a number of benefits, including lower emotional exhaustion […] and more effective coping strategies […] Married coworkers are an interesting population to examine, largely because their work and family roles are so highly integrated […]. As a result, both resources and demands are more likely to spill over between the work and family role for married coworkers […] Janning and Neely (2006) found that married coworkers were more likely to talk about work-related issues while at home than married couples that had no work-related link.”
“Negative exchanges [between coworkers] are characterized by behaviors that are generally undesirable, disrespectful, and harmful to the focal employee or employees. Scholars have found that these negative exchanges influence the same outcomes as positive, supporting exchanges, but in opposite directions. For instance, in their recent meta-analysis of 161 independent studies, Chiaburu and Harrison (2008) found that antagonistic coworker exchanges are negatively related to job satisfaction, organizational commitment, and task performance and positively related to absenteeism, intent to quit, turnover, and counterproductive work behaviors. Unfortunately, despite the recent popularity of the negative exchange research, this literature still lacks construct clarity and definitional precision. […] Because these behaviors have generally referred to acts that impact both coworkers and the organization as a whole, much of this work fails to distinguish social interactions targeting specific individuals within the organization from the nonsocial behaviors explicitly targeting the overall organization. This is unfortunate given that coworker-focused actions and organization-focused actions represent unique dimensions of organizational behavior […] negative exchanges are likely to be preceded by certain antecedents. […] Antecedents may stem from characteristics of the enactor, of the target, or of the context in which the behaviors occur. For example, to the extent that enactors are low on socially relevant personality traits such as agreeableness, emotional stability, or extraversion […], they may be more prone to initiate a negative exchange. Likewise, an enactor who is a high Machiavellian may initiate a negative exchange with the goal of gaining power or establishing control over the target. Antagonistic behaviors may also occur as reciprocation for a previous attack (real or imagined) or as a proactive deterrent against a potential future negative behavior from the target. Similarly, enactors may initiate antagonism based on their perceptions of a coworker’s behavioral characteristics such as suboptimal productivity or weak work ethic. […] The reward system can also play a role as an antecedent condition for antagonism. When coworkers are highly interdependent and receive rewards based on the performance of the group as opposed to each individual, the incidence of antagonism may increase when there is substantial variance in performance among coworkers.”
“[E]mpirical evidence suggests that some people have certain traits that make them more vulnerable to coworker attacks. For example, employees with low self-esteem, low emotional stability, high introversion, or high submissiveness are more inclined to be the recipients of negative coworker behaviors […]. Furthermore, research also shows that people who engage in negative behaviors are likely to also become the targets of these behaviors […] Two of the most commonly studied workplace attitudes are employee job satisfaction […] and affective organizational commitment […] Chiaburu and Harrison (2008) linked general coworker antagonism with both attitudes. Further, the specific behaviors of bullying and incivility have also been found to adversely affect both job satisfaction and organizational commitment […]. A variety of behavioral outcomes have also been identified as outcomes of coworker antagonism. Withdrawal behaviors such as absenteeism, intention to quit, turnover, effort reduction […] are typical responses […] those who have been targeted by aggression are more likely to engage in aggression. […] Feelings of anger, fear, and negative mood have also been shown to mediate the effects of interpersonal mistreatment on behaviors such as withdrawal and turnover […] [T]he combination of enactor and target characteristics is likely to play an antecedent role to these exchanges. For instance, research in the diversity area suggests that people tend to be more comfortable around those with whom they are similar and less comfortable around people with whom they are dissimilar […] there may be a greater incidence of coworker antagonism in more highly diverse settings than in settings characterized by less diversity. […] research has suggested that antagonistic behaviors, while harmful to the target or focal employee, may actually be beneficial to the enactor of the exchange. […] Krischer, Penney, and Hunter (2010) recently found that certain types of counterproductive work behaviors targeting the organization may actually provide employees with a coping mechanism that ultimately reduces their level of emotional exhaustion.”
“CWB [counterproductive work behaviors] toward others is composed of volitional acts that harm people at work; in our discussion this would refer to coworkers. […] person-oriented organizational citizenship behaviors (OCB; Organ, 1988) consist of behaviors that help others in the workplace. This might include sharing job knowledge with a coworker or helping a coworker who had too much to do […] Social support is often divided into the two forms of emotional support that helps people deal with negative feelings in response to demanding situations versus instrumental support that provides tangible aid in directly dealing with work demands […] one might expect that instrumental social support would be more strongly related to positive exchanges and positive relationships. […] coworker social support […] has [however] been shown to relate to strains (burnout) in a meta-analysis (Halbesleben, 2006). […] Griffin et al. suggested that low levels of the Five Factor Model […] dimensions of agreeableness, emotional stability, and extraversion might all contribute to negative behaviors. Support can be found for the connection between two of these personality characteristics and CWB. […] Berry, Ones, and Sackett (2007) showed in their meta-analysis that person-focused CWB (they used the term deviance) had significant mean correlations of –.20 with emotional stability and –.36 with agreeableness […] there was a significant relationship with conscientiousness (r = –.19). Thus, agreeable, conscientious, and emotionally stable individuals are less likely to engage in CWB directed toward people and would be expected to have fewer negative exchanges and better relationships with coworkers. […] Halbesleben […] suggests that individuals high on the Five Factor Model […] dimensions of agreeableness and conscientiousness would have more positive exchanges because they are more likely to engage in helping behavior. […] a meta-analysis has shown that both of these personality variables relate to the altruism factor of OCB in the direction expected […]. Specifically, the mean correlations of OCB were .13 for agreeableness and .22 for conscientiousness. Thus, individuals high on these two personality dimensions should have more positive coworker exchanges.”
“There is a long history of research in social psychology supporting the idea that people tend to be attracted to, bond, and form friendships with others they believe to be similar […], and this is true whether the similarity is rooted in demographics that are fairly easy to observe […] or in attitudes, beliefs, and values that are more difficult to observe […] Social network scholars refer to this phenomenon as homophily, or the notion that “similarity breeds connection” […] although evidence of homophily has been found to exist in many different types of relationships, including marriage, frequency of communication, and career support, it is perhaps most evident in the formation of friendships […] We extend this line of research and propose that, in a team context that provides opportunities for tie formation, greater levels of perceived similarity among team members will be positively associated with the number of friendship ties among team members. […] A chief function of friendship ties is to provide an outlet for individuals to disclose and manage emotions. […] friendship is understood as a form of support that is not related to work tasks directly; rather, it is a “backstage resource” that allows employees to cope with demands by creating distance between them and their work roles […]. Thus, we propose that friendship network ties will be especially important in providing the type of coping resources that should foster team member well-being. Unfortunately, however, friendship network ties negatively impact team members’ ability to focus on their work tasks, and, in turn, this detracts from taskwork. […] When friends discuss nonwork topics, these individuals will be distracted from work tasks and will be exposed to off-task information exchanged in informal relationships that is irrelevant for performing one’s job. Additionally, distractions can hinder individuals’ ability to become completely engaged in their work (Jett & George).”
“Although teams are designed to meet important goals for both companies and their employees, not all team members work together well.
Teams are frequently “cruel to their members” […] through a variety of negative team member exchanges (NTMEs) including mobbing, bullying, incivility, social undermining, and sexual harassment. […] Team membership offers identity […], stability, and security — positive feelings that often elevate work teams to powerful positions in employees’ lives […], so that members are acutely aware of how their teammates treat them. […] NTMEs may evoke stronger emotional, attitudinal, and behavioral consequences than negative encounters with nonteam members. In brief, team members who are targeted for NTMEs are likely to experience profound threats to personal identity, security, and stability […] when a team member targets another for negative interpersonal treatment, the target is likely to perceive that the entire group is behind the attack rather than the specific instigator alone […] Studies have found that NTMEs […] are associated with poor psychological outcomes such as depression; undesirable work attitudes such as low affective commitment, job dissatisfaction, and low organization-based self-esteem; and counterproductive behaviors such as deviance, job withdrawal, and unethical behavior […] Some initial evidence has also indicated that perceptions of rejection mediate the effects of NTMEs on target outcomes […] Perceptions of the comparative treatment of other team members are an important factor in reactions to NTMEs […]. When targets perceive they are “singled out,” NTMEs will cause more pronounced effects […] A significant body of literature has suggested that individuals guide their own behaviors through environmental social cues that they glean from observing the norms and values of others. Thus, the negative effects of NTMEs may extend beyond the specific targets; NTMEs can spread contagiously to other team members […]. The more interdependent the social actors in the team setting, the stronger and more salient will be the social cues […] [There] is evidence that as team members see others enacting NTMEs, their inhibitions against such behaviors are lowered.”
Personal Relationships… (I)
“Across subdisciplines of psychology, research finds that positive, fulfilling, and satisfying relationships contribute to life satisfaction, psychological health, and physical well-being whereas negative, destructive, and unsatisfying relationships have a whole host of detrimental psychological and physical effects. This is because humans possess a fundamental “need to belong” […], characterized by the motivation to form and maintain lasting, positive, and significant relationships with others. The need to belong is fueled by frequent and pleasant relational exchanges with others and thwarted when one feels excluded, rejected, and hurt by others. […] This book uses research and theory on the need to belong as a foundation to explore how five different types of relationships influence employee attitudes, behaviors, and well-being. They include relationships with supervisors, coworkers, team members, customers, and individuals in one’s nonwork life. […] This book is written for a scientist–practitioner audience and targeted to both researchers and human resource management professionals. The contributors highlight both theoretical and practical implications in their respective chapters, with a common emphasis on how to create and sustain an organizational climate that values positive relationships and deters negative interpersonal experiences. Due to the breadth of topics covered in this edited volume, the book is also appropriate for advanced specialty undergraduate or graduate courses on I/O psychology, human resource management, and organizational behavior.”
…
The kind of stuff covered in books like this one relates closely to social stuff I lack knowledge about and/or is just not very good at handling. I don’t think too highly of this book’s coverage so far, but that’s at least partly due to the kinds of topics covered – it is what it is.
Below I have added some quotes from the first few chapters of the book.
…
“Work relationships are important to study in that they can exert a strong influence on employees’ attitudes and behaviors […].The research evidence is robust and consistent; positive relational interactions at work are associated with more favorable work attitudes, less work-related strain, and greater well-being (for reviews see Dutton & Ragins, 2007; Grant & Parker, 2009). On the other side of the social ledger, negative relational interactions at work induce greater strain reactions, create negative affective reactions, and reduce well-being […]. The relationship science literature is clear, social connection has a causal effect on individual health and well-being”.
“[One] way to view relationships is to consider the different dimensions by which relationships vary. An array of dimensions that underlie relationships has been proposed […] Affective tone reflects the degree of positive and negative feelings and emotions within the relationship […] Relationships and groups marked by greater positive affective tone convey more enthusiasm, excitement, and elation for each other, while relationships consisting of more negative affective tone express more fear, distress, and scorn. […] Emotional carrying capacity refers to the extent that the relationship can handle the expression of a full range of negative and position emotions as well as the quantity of emotion expressed […]. High-quality relationships have the ability to withstand the expression of more emotion and a greater variety of emotion […] Interdependence involves ongoing chains of mutual influence between two people […]. Degree of relationship interdependency is reflected through frequency, strength, and span of influence. […] A high degree of interdependence is commonly thought to be one of the hallmarks of a close relationship […] Intimacy is composed of two fundamental components: self-disclosure and partner responsiveness […]. Responsiveness involves the extent that relationship partners understand, validate, and care for one another. Disclosure refers to verbal communications of personally relevant information, thoughts, and feelings. Divulging more emotionally charged information of a highly personal nature is associated with greater intimacy […]. Disclosure tends to proceed from the superficial to the more intimate and expands in breadth over time […] Power refers to the degree that dominance shapes the relationship […] relationships marked by a power differential are more likely to involve unidirectional interactions. Equivalent power tends to facilitate bidirectional exchanges […] Tensility is the extent that the relationship can bend and endure strain in the face of challenges and setbacks […]. Relationship tensility contributes to psychological safety within the relationship. […] Trust is the belief that relationship partners can be depended upon and care about their partner’s needs and interests […] Relationships that include a great deal of trust are stronger and more resilient. A breach of trust can be one of the most difficult relationships challenges to overcome (Pratt & dirks, 2007).”
“Relationships are separate entities from the individuals involved in the relationships. The relationship unit (typically a dyad) operates at a different level of analysis from the individual unit. […] For those who conduct research on groups or organizations, it is clear that operations at a group level […] operate at a different level than individual psychology, and it is not merely the aggregate of the individuals involved in the relationship. […] operations at one level (e.g., relationships) can influence behavior at the other level (e.g., individual). […] relationships are best thought of as existing at their own level of analysis, but one that interacts with other levels of analysis, such as individual and group or cultural levels. Relationships cannot be reduced to the actions of the individuals in them or the social structures where they reside but instead interact with the individual and group processes in interesting ways to produce behaviors. […] it is challenging to assess causality via experimental procedures when studying relationships. […] Experimental procedures are crucial for making inferences of causation but are particularly difficult in the case of relationships because it is tough to manipulate many important relationships (e.g., love, marriage, sibling relationships). […] relationships are difficult to observe at the very beginning and at the end, so methods have been developed to facilitate this.”
“[T]he organizational research could […] benefit from the use of theoretical models from the broader relationships literature. […] Interdependence theory is hardly ever seen in organizations. There was some fascinating work in this area a few decades ago, especially in interdependence theory with the investment model […]. This work focused on the precursors of commitment in the workplace and found that, like romantic relationships, the variables of satisfaction, investments, and alternatives played key roles in this process. The result is that when satisfaction and investments are high and alternative opportunities are low, commitment is high. However, it also means that if investments are sufficiently high and alternatives are sufficiently low, then satisfaction can by lowered and commitment will remain high — hence, the investment model is useful for understanding exploitation (Rusbult, Campbell, & Price, 1990).”
“Because they cross formal levels in the organizational hierarchy, supervisory relationships necessarily involve an imbalance in formal power. […] A review by Keltner, Gruenfeld, and Anderson (2003) suggests that power affects how people experience emotions, whether they attend more to rewards or threats, how they process information, and the extent to which they inhibit their behavior around others. The literature clearly suggests that power influences affect, cognition, and behavior in ways that might tend to constrain the formation of positive relationships between individuals with varying degrees of power. […] The power literature is clear in showing that more powerful individuals attend less to their social context, including the people in it, than do less powerful individuals, and the literature suggests that supervisors (compared with subordinates) might tend to place less value on the relationship and be less attuned to their partner’s needs. Yet the formal power accorded to supervisors by the organization — via the supervisory role — is accompanied by the role prescribed responsibility for the performance, motivation, and well-being of subordinates. Thus, the accountability for the formation of a positive supervisory relationship lies more heavily with the supervisor. […] As we examine the qualities of positive supervisory relationships, we make a clear distinction between effective supervisory behaviors and positive supervisory relationships. This is an important distinction […] a large body of leadership research has focused on traits or behaviors of supervisors […] and the affective, motivational, and behavioral responses of employees to those behaviors, with little attention paid to the interactions between the two. There are two practical implications of moving the focus from individuals to relationships: (1) supervisors who use “effective” leadership behaviors may or may not have positive relationships with employees; and (2) supervisors who have a positive relationship with one employee may not have equally positive relationships with other employees, even if they use the same “effective” behaviors.”
“There is a large and well-developed stream of research that focuses explicitly on exchanges between supervisors and the employees who report directly to them. Leader–member exchange theory addresses the various types of functional relationships that can be formed between supervisors and subordinates. A core assumption of LMX theory is that supervisors do not have the time or resources to develop equally positive relationships with all subordinates. Thus, to minimize their investment and yield the greatest results for the organization, supervisors would develop close relationships with only a few subordinates […] These few high-quality relationships are marked by high levels of trust, loyalty, and support, whereas the balance of supervisory relationships are contractual in nature and depends on timely rewards allotted by supervisors in direct exchange for desirable behaviors […] There has been considerable confusion and debate in the literature about LMX theory and the construct validity of LMX measures […] Despite shortcomings in LMX research, it is [however] clear that supervisors form relationships of varying quality with subordinates […] Among factors associated with high LMX are the supervisor’s level of agreeableness […] and the employee’s level of extraversion […], feedback seeking […], and (negatively) negative affectivity […]. Those who perceived similarity in terms of family, money, career strategies, goals in life, education […], and gender […] also reported high LMX. […] Employee LMX is strongly related to attitudes, such as job satisfaction […] Supporting the notion that a positive supervisory relationship is good for employees, the LMX literature is replete with studies linking high LMX with thriving and autonomous motivation. […] The premise of the LMX research is that supervisory resources are limited and high-quality relationships are demanding. Thus, supervisor will be most effective when they allocate their resources efficiently and effectively, forming some high-quality and some instrumental relationships. But the empirical research from the lMX literature provides little (if any) evidence that supervisors who differentiate are more effective”.
“The norm of negative reciprocity obligates targets of harm to reciprocate with actions that produce roughly equivalent levels of harm — if someone is unkind to me, I should be approximately as unkind to him or her. […] But the trajectory of negative reciprocity differs in important ways when there are power asymmetries between the parties involved in a negative exchange relationship. The workplace revenge literature suggests that low-power targets of hostility generally withhold retaliatory acts. […] In exchange relationships where one actor is more dependent on the other for valued resources, the dependent/less powerful actor’s ability to satisfy his or her self-interests will be constrained […]. Subordinate targets of supervisor hostility should therefore be less able (than supervisor targets of subordinate hostility) to return the injuries they sustain […] To the extent subordinate contributions to negative exchanges are likely to trigger disciplinary responses by the supervisor target (e.g., reprimands, demotion, transfer, or termination), we can expect that subordinates will withhold negative reciprocity.”
“In the last dozen years, much has been learned about the contributions that supervisors make to negative exchanges with subordinates. […] Several dozen studies have examined the consequences of supervisor contributions to negative exchanges. This work suggests that exposure to supervisor hostility is negatively related to subordinates’ satisfaction with the job […], affective commitment to the organization […], and both in-role and extra-role performance contributions […] and is positively related to subordinates’ psychological distress […], problem drinking […], and unit-level counterproductive work behavior […]. Exposure to supervisor hostility has also been linked with family undermining behavior — employees who are the targets of abusive supervision are more likely to be hostile toward their own family members […] Most studies of supervisor hostility have accounted for moderating factors — individual and situational factors that buffer or exacerbate the effects of exposure. For example, Tepper (2000) found that the injurious effects of supervisor hostility on employees’ attitudes and strain reactions were stronger when subordinates have less job mobility and therefore feel trapped in jobs that deplete their coping resources. […] Duffy, Ganster, Shaw, Johnson, and Pagon (2006) found that the effects of supervisor hostility are more pronounced when subordinates are singled out rather than targeted along with multiple coworkers. […] work suggests that the effects of abusive supervision on subordinates’ strain reactions are weaker when subordinates employ impression management strategies […] and more confrontational (as opposed to avoidant) communication tactics […]. It is clear that not all subordinates react the same way to supervisor hostility and characteristics of subordinates and the context influence the trajectory of subordinates’ responses. […] In a meta-analytic examination of studies of the correlates of supervisor-directed hostility, Herschovis et al. (2007) found support for the idea that subordinates who believe that they have been the target of mistreatment are more likely to lash out at their supervisors. […] perhaps just as interesting as the associations that have been uncovered are several hypothesized associations that have not emerged. Greenberg and Barling (1999) found that supervisor-directed aggression was unrelated to subordinates’ alcohol consumption, history of aggression, and job security. Other work has revealed mixed results for the prediction that subordinate self-esteem will negatively predict supervisor-directed hostility (Inness, Barling, & Turner, 2005). […] Negative exchanges between supervisors and subordinates do not play out in isolation — others observe them and are affected by them. Yet little is known about the affective, cognitive, and behavioral responses of third parties to negative exchanges with supervisors.”
Prevention of Late-Life Depression (II)
Some more observations from the book:
…
“In contrast to depression in childhood and youth when genetic and developmental vulnerabilities play a significant role in the development of depression, the development of late-life depression is largely attributed to its interactions with acquired factors, especially medical illness [17, 18]. An analysis of the WHO World Health Survey indicated that the prevalence of depression among medical patients ranged from 9.3 to 23.0 %, significantly higher than that in individuals without medical conditions [19]. Wells et al. [20] found in the Epidemiologic Catchment Area Study that the risk of developing lifetime psychiatric disorders among individuals with at least one medical condition was 27.9 % higher than among those without medical conditions. […] Depression and disability mutually reinforce the risk of each other, and adversely affect disease progression and prognosis [21, 25]. […] disability caused by medical conditions serves as a risk factor for depression [26]. When people lose their normal sensory, motor, cognitive, social, or executive functions, especially in a short period of time, they can become very frustrated or depressed. Inability to perform daily tasks as before decreases self-esteem, reduces independence, increases the level of psychological stress, and creates a sense of hopelessness. On the other hand, depression increases the risk for disability. Negative interpretation, attention bias, and learned hopelessness of depressed persons may increase risky health behaviors that exacerbate physical disorders or disability. Meanwhile, depression-related cognitive impairment also affects role performance and leads to functional disability [25]. For example, Egede [27] found in the 1999 National Health Interview Survey that the risk of having functional disability among patients with the comorbidity of diabetes and depression were approximately 2.5–5 times higher than those with either depression or diabetes alone. […] A leading cause of disability among medical patients is pain and pain-related fears […] Although a large proportion of pain complaints can be attributed to physiological changes from physical disorders, psychological factors (e.g., attention, interpretation, and coping skills) play an important role in perception of pain […] Bair et al. [31] indicated in a literature review that the prevalence of pain was higher among depressed patients than non-depressed patients, and the prevalence of major depression was also higher among pain patients comparing to those without pain complaints.”
“Alcohol use has more serious adverse health effects on older adults than other age groups, since aging-related physiological changes (e.g. reduced liver detoxification and renal clearance) affect alcohol metabolism, increase the blood concentration of alcohol, and magnify negative consequences. More importantly, alcohol interacts with a variety of frequently prescribed medications potentially influencing both treatment and adverse effects. […] Due to age-related changes in pharmacokinetics and pharmacodynamics, older adults are a vulnerable population to […] adverse drug effects. […] Adverse drug events are frequently due to failure to adjust dosage or to account for drug–drug interactions in older adults [64]. […] Loneliness […] is considered as an independent risk factor for depression [46, 47], and has been demonstrated to be associated with low physical activity, increased cardiovascular risks, hyperactivity of the hypothalamic-pituitary-adrenal axis, and activation of immune response [for details, see Cacioppo & Patrick’s book on these topics – US] […] Hopelessness is a key concept of major depression [54], and also an independent risk factor of suicidal ideation […] Hopelessness reduces expectations for the future, and negatively affects judgment for making medical and behavioral decisions, including non-adherence to medical regimens or engaging in unhealthy behaviors.”
“Co-occurring depression and medical conditions are associated with more functional impairment and mortality than expected from the severity of the medical condition alone. For example, depression accompanying diabetes confers increased functional impairment [27], complications of diabetes [65, 66], and mortality [67–71]. Frasure-Smith and colleagues highlighted the prognostic importance of depression among persons who had sustained a myocardial infarction (MI), finding that depression was a significant predictor of mortality at both 6 and 18 months post MI [72, 73]. Subsequent follow-up studies have borne out the increased risk conferred by depression on the mortality of patients with cardiovascular disease [10, 74, 75]. Over the course of a 2-year follow-up interval, depression contributed as much to mortality as did myocardial infarction or diabetes, with the population attributable fraction of mortality due to depression approximately 13 % (similar to the attributable risk associated with heart attack at 11 % and diabetes at 9 %) [76]. […] Although the bidirectional relationship between physical disorders and depression has been well known, there are still relatively few randomized controlled trials on preventing depression among medically ill patients. […] Rates of attrition [in post-stroke depression prevention trials has been observed to be] high […] Stroke, acute coronary syndrome, cancer, and other conditions impose a variety of treatment burdens on patients so that additional interventions without direct or immediate clinical effects may not be acceptable [95]. So even with good participation rates, lack of adherence to the intervention might limit effects.”
“Late-life depression (LLD) is a heterogeneous disease, with multiple risk factors, etiologies, and clinical features. It has been recognized for many years that there is a significant relationship between the presence of depression and cerebrovascular disease in older adults [1, 2]. This subtype of LLD was eventually termed “vascular depression.” […] There have been a multitude of studies associating white matter abnormalities with depression in older adults using MRI technology to visualize lesions, or what appear as hyperintensities in the white matter on T2-weighted scans. A systematic review concluded that white matter hyperintensities (WMH) are more common and severe among older adults with depression compared to their non-depressed peers [9]. […] WMHs are associated with older age [13] and cerebrovascular risk factors, including diabetes, heart disease, and hypertension [14–17]. White matter severity and extent of WMH volume has been related to the severity of depression in late life [18, 19]. For example, among 639 older, community-dwelling adults, white matter lesion (WML) severity was found to predict depressive episodes and symptoms over a 3-year period [19]. […] Another way of investigating white matter integrity is with diffusion tensor imaging (DTI), which measures the diffusion of water in tissues and allows for indirect evidence of the microstructure of white matter, most commonly represented as fractional anisotropy (FA) and mean diffusivity (MD). DTI may be more sensitive to white matter pathology than is quantification of WMH […] A number of studies have found lower FA in widespread regions among individuals with LLD relative to controls [34, 36, 37]. […] lower FA has been associated with poorer performance on measures of cognitive functioning among patients with LLD [35, 38–40] and with measures of cerebrovascular risk severity. […] It is important to recognize that FA reflects the organization of fiber tracts, including fiber density, axonal diameter, or myelination in white matter. Thus, lower FA can result from multiple pathophysiological sources [42, 43]. […] Together, the aforementioned studies provide support for the vascular depression hypothesis. They demonstrate that white matter integrity is reduced in patients with LLD relative to controls, is somewhat specific to regions important for cognitive and emotional functioning, and is associated with cognitive functioning and depression severity. […] There is now a wealth of evidence to support the association between vascular pathology and depression in older age. While the etiology of depression in older age is multifactorial, from the epidemiological, neuroimaging, behavioral, and genetic evidence available, we can conclude that vascular depression represents one important subtype of LLD. The mechanisms underlying the relationship between vascular pathology and depression are likely multifactorial, and may include disrupted connections between key neural regions, reduced perfusion of blood to key brain regions integral to affective and cognitive processing, and inflammatory processes.”
“Cognitive changes associated with depression have been the focus of research for decades. Results have been inconsistent, likely as a result of methodological differences in how depression is diagnosed and cognitive functioning measured, as well as the effects of potential subtypes and the severity of depression […], though deficits in executive functioning, learning and memory, and attention have been associated with depression in most studies [75]. In older adults, additional confounding factors include the potential presence of primary degenerative disorders, such as Alzheimer’s disease, which can pose a challenge to differential diagnosis in its early stages. […] LLD with cognitive dysfunction has been shown to result in greater disability than depressive symptoms alone [6], and MCI [mild cognitive impairment, US] with co-occurring LLD has been shown to double the risk of developing Alzheimer’s disease (AD) compared to MCI alone [86]. The conversion from MCI to AD also appears to occur earlier in patients with cooccurring depressive symptoms, as demonstrated by Modrego & Ferrandez [86] in their prospective cohort study of 114 outpatients diagnosed with amnestic MCI. […] Given accruing evidence for abnormal functioning of a number of cortical and subcortical networks in geriatric depression, of particular interest is whether these abnormalities are a reflection of the actively depressed state, or whether they may persist following successful resolution of symptoms. To date, studies have investigated this question through either longitudinal investigation of adults with geriatric depression, or comparison of depressed elders who are actively depressed versus those who have achieved symptom remission. Of encouragement, successful treatment has been reliably associated with normalization of some aspects of disrupted network functioning. For example, successful antidepressant treatment is associated with reduction of the elevated cerebral glucose metabolism observed during depressed states (e.g., [71–74]), with greater symptom reduction associated with greater metabolic change […] Taken together, these studies suggest that although a subset of the functional abnormalities observed during the LLD state may resolve with successful treatment, other abnormalities persist and may be tied to damage to the structural connectivity in important affective and cognitive networks. […] studies suggest a chronic decrement in cognitive functioning associated with LLD that is not adequately addressed through improvement of depressive symptoms alone.”
“A review of the literature on evidence-based treatments for LLD found that about 50 % of patients improved on antidepressants, but that the number needed to treat (NNT) was quite high (NNT = 8, [139]) and placebo effects were significant [140]. Additionally, no difference was demonstrated in the effectiveness of one antidepressant drug class over another […], and in one-third of patients, depression was resistant to monotherapy [140]. The addition of medications or switching within or between drug classes appears to result in improved treatment response for these patients [140, 141]. A meta-analysis of patient-level variables demonstrated that duration of depressive symptoms and baseline depression severity significantly predicts response to antidepressant treatment in LLD, with chronically depressed older patients with moderate-to-severe symptoms at baseline experiencing more improvement in symptoms than mildly and acutely depressed patients [142]. Pharmacological treatment response appears to range from incomplete to poor in LLD with co-occurring cognitive impairment.”
“[C]ompared to other formulations of prevention, such as primary, secondary, or tertiary — in which interventions are targeted at the level of disease/stage of disease — the IOM conceptual framework involves interventions that are targeted at the level of risk in the population [2]. […] [S]elective prevention studies have an important “numbers” advantage — similar to that of indicated prevention trials: the relatively high incidence of depression among persons with key risk markers enables investigator to test interventions with strong statistical power, even with somewhat modest sample sizes. This fact was illustrated by Schoevers and colleagues [3], in which the authors were able to account for nearly 50 % of total risk of late-life depression with consideration of only a handful of factors. Indeed, research, largely generated by groups in the Netherlands and the USA, has identified that selective prevention may be one of the most efficient approaches to late-life depression prevention, as they have estimated that targeting persons at high risk for depression — based on risk markers such as medical comorbidity, low social support, or physical/functional disability — can yield theoretical numbers needed to treat (NNTs) of approximately 5–7 in primary care settings [4–7]. […] compared to the findings from selective prevention trials targeting older persons with general health/medical problems, […] trials targeting older persons based on sociodemographic risk factors have been more mixed and did not reveal as consistent a pattern of benefits for selective prevention of depression.”
“Few of the studies in the existing literature that involve interventions to prevent depression and/or reduce depressive symptoms in older populations have included economic evaluations [13]. The identification of cost-effective interventions to provide to groups at high risk for depression is an important public health goal, as such treatments may avert or reduce a significant amount of the disease burden. […] A study by Katon and colleagues [8] showed that elderly patients with either subsyndromal or major depression had significantly higher medical costs during the previous 6 months than those without depression; total healthcare costs were $1,045 to $1,700 greater, and total outpatient/ambulatory costs ranged from being $763 to $979 more, on average. Depressed patients had greater usage of health resources in every category of care examined, including those that are not mental health-related, such as emergency department visits. No difference in excess costs was found between patients with a DSM-IV depressive disorder and those with depressive symptoms only, however, as mean total costs were 51 % higher in the subthreshold depression group (95 % CI = 1.39–1.66) and 49 % higher in the MDD/dysthymia group (95 % CI = 1.28–1.72) than in the nondepressed group [8]. In a similar study, the usage of various types of health services by primary care patients in the Netherlands was assessed, and average costs were determined to be €1,403 more in depressed individuals versus control patients [21]. Study investigators once again observed that patients with depression had greater utilization of both non-mental and mental healthcare services than controls.”
“In order for routine depression screening in the elderly to be cost-effective […] appropriate follow-up measures must be taken with those who screen positive, including a diagnostic interview and/or referral to a mental health professional [this – the necessity/requirement of proper follow-up following screens in order for screening to be cost-effective – is incidentally a standard result in screening contexts, see also Juth & Munthe’s book – US] [23, 25]. For example, subsequent steps may include initiation of psychotherapy or antidepressant treatment. Thus, one reason that the USPSTF does not recommend screening for depression in settings where proper mental health resources do not exist is that the evidence suggests that outcomes are unlikely to improve without effective follow-up care […] as per the USPSTF suggestion, Medicare will only cover the screening when the appropriate supports for proper diagnosis and treatment are available […] In order to determine which interventions to prevent and treat depression should be provided to those who screen positive for depressive symptoms and to high-risk populations in general, cost-effectiveness analyses must be completed for a variety of different treatments and preventive measures. […] questions remain regarding whether annual versus other intervals of screening are most cost-effective. With respect to preventive interventions, the evidence to date suggests that these are cost-effective in settings where those at the highest risk are targeted.”
Prevention of Late-Life Depression (I)
“Late-life depression is a common and highly disabling condition and is also associated with higher health care utilization and overall costs. The presence of depression may complicate the course and treatment of comorbid major medical conditions that are also highly prevalent among older adults — including diabetes, hypertension, and heart disease. Furthermore, a considerable body of evidence has demonstrated that, for older persons, residual symptoms and functional impairment due to depression are common — even when appropriate depression therapies are being used. Finally, the worldwide phenomenon of a rapidly expanding older adult population means that unprecedented numbers of seniors — and the providers who care for them — will be facing the challenge of late-life depression. For these reasons, effective prevention of late-life depression will be a critical strategy to lower overall burden and cost from this disorder. […] This textbook will illustrate the imperative for preventing late-life depression, introduce a broad range of approaches and key elements involved in achieving effective prevention, and provide detailed examples of applications of late-life depression prevention strategies”.
…
I gave the book two stars on goodreads. There are 11 chapters in the book, written by 22 different contributors/authors, so of course there’s a lot of variation in the quality of the material included; the two star rating was an overall assessment of the quality of the material, and the last two chapters – but in particular chapter 10 – did a really good job convincing me that the the book did not deserve a 3rd star (if you decide to read the book, I advise you to skip chapter 10). In general I think many of the authors are way too focused on statistical significance and much too hesitant to report actual effect sizes, which are much more interesting. Gender is mentioned repeatedly throughout the coverage as an important variable, to the extent that people who do not read the book carefully might think this is one of the most important variables at play; but when you look at actual effect sizes, you get reported ORs of ~1.4 for this variable, compared to e.g. ORs in the ~8-9 for the bereavement variable (see below). You can quibble about population attributable fraction and so on here, but if the effect size is that small it’s unlikely to be all that useful in terms of directing prevention efforts/resource allocation (especially considering that women make out the majority of the total population in these older age groups anyway, as they have higher life expectancy than their male counterparts).
Anyway, below I’ve added some quotes and observations from the first few chapters of the book.
…
“Meta-analyses of more than 30 randomized trials conducted in the High Income Countries show that the incidence of new depressive and anxiety disorders can be reduced by 25–50 % over 1–2 years, compared to usual care, through the use of learning-based psychotherapies (such as interpersonal psychotherapy, cognitive behavioral therapy, and problem solving therapy) […] The case for depression prevention is compelling and represents the key rationale for this volume: (1) Major depression is both prevalent and disabling, typically running a relapsing or chronic course. […] (2) Major depression is often comorbid with other chronic conditions like diabetes, amplifying the disability associated with these conditions and worsening family caregiver burden. (3) Depression is associated with worse physical health outcomes, partly mediated through poor treatment adherence, and it is associated with excess mortality after myocardial infarction, stroke, and cancer. It is also the major risk factor for suicide across the life span and particularly in old age. (4) Available treatments are only partially effective in reducing symptom burden, sustaining remission, and averting years lived with disability.”
“[M]any people suffering from depression do not receive any care and approximately a third of those receiving care do not respond to current treatments. The risk of recurrence is high, also in older persons: half of those who have experienced a major depression will experience one or even more recurrences [4]. […] Depression increases the risk at death: among people suffering from depression the risk of dying is 1.65 times higher than among people without a depression [7], with a dose-response relation between severity and duration of depression and the resulting excess mortality [8]. In adults, the average length of a depressive episode is 8 months but among 20 % of people the depression lasts longer than 2 years [9]. […] It has been estimated that in Australia […] 60 % of people with an affective disorder receive treatment, and using guidelines and standards only 34 % receives effective treatment [14]. This translates in preventing 15 % of Years Lived with Disability [15], a measure of disease burden [14] and stresses the need for prevention [16]. Primary health care providers frequently do not recognize depression, in particular among elderly. Older people may present their depressive symptoms differently from younger adults, with more emphasis on physical complaints [17, 18]. Adequate diagnosis of late-life depression can also be hampered by comorbid conditions such as Parkinson and dementia that may have similar symptoms, or by the fact that elderly people as well as care workers may assume that “feeling down” is part of becoming older [17, 18]. […] Many people suffering from depression do not seek professional help or are not identied as depressed [21]. Almost 14 % of elderly people living in community-type living suffer from a severe depression requiring clinical attention [22] and more than 50 % of those have a chronic course [4, 23]. Smit et al. reported an incidence of 6.1 % of chronic or recurrent depression among a sample of 2,200 elderly people (ages 55–85) [21].”
“Prevention differs from intervention and treatment as it is aimed at general population groups who vary in risk level for mental health problems such as late-life depression. The Institute of Medicine (IOM) has introduced a prevention framework, which provides a useful model for comprehending the different objectives of the interventions [29]. The overall goal of prevention programs is reducing risk factors and enhancing protective factors.
The IOM framework distinguishes three types of prevention interventions: (1) universal preventive interventions, (2) selective preventive interventions, and (3) indicated preventive interventions. Universal preventive interventions are targeted at the general audience, regardless of their risk status or the presence of symptoms. Selective preventive interventions serve those sub-populations who have a significantly higher than average risk of a disorder, either imminently or over a lifetime. Indicated preventive interventions target identified individuals with minimal but detectable signs or symptoms suggesting a disorder. This type of prevention consists of early recognition and early intervention of the diseases to prevent deterioration [30]. For each of the three types of interventions, the goal is to reduce the number of new cases. The goal of treatment, on the other hand, is to reduce prevalence or the total number of cases. By reducing incidence you also reduce prevalence [5]. […] prevention research differs from treatment research in various ways. One of the most important differences is the fact that participants in treatment studies already meet the criteria for the illness being studied, such as depression. The intervention is targeted at improvement or remission of the specific condition quicker than if no intervention had taken place. In prevention research, the participants do not meet the specific criteria for the illness being studied and the overall goal of the intervention is to prevent the development of a clinical illness at a lower rate than a comparison group [5].”
“A couple of risk factors [for depression] occur more frequently among the elderly than among young adults. The loss of a loved one or the loss of a social role (e.g., employment), decrease of social support and network, and the increasing change of isolation occur more frequently among the elderly. Many elderly also suffer from physical diseases: 64 % of elderly aged 65–74 has a chronic disease [36] […]. It is important to note that depression often co-occurs with other disorders such as physical illness and other mental health problems (comorbidity). Losing a spouse can have significant mental health effects. Almost half of all widows and widowers during the first year after the loss meet the criteria for depression according to the DSM-IV [37]. Depression after loss of a loved one is normal in times of mourning. However, when depressive symptoms persist during a longer period of time it is possible that a depression is developing. Zisook and Shuchter found that a year after the loss of a spouse 16 % of widows and widowers met the criteria of a depression compared to 4 % of those who did not lose their spouse [38]. […] People with a chronic physical disease are also at a higher risk of developing a depression. An estimated 12–36 % of those with a chronic physical illness also suffer from clinical depression [40]. […] around 25 % of cancer patients suffer from depression [40]. […] Depression is relatively common among elderly residing in hospitals and retirement- and nursing homes. An estimated 6–11 % of residents have a depressive illness and among 30 % have depressive symptoms [41]. […] Loneliness is common among the elderly. Among those of 60 years or older, 43 % reported being lonely in a study conducted by Perissinotto et al. […] Loneliness is often associated with physical and mental complaints; apart from depression it also increases the chance of developing dementia and excess mortality [43].”
“From the public health perspective it is important to know what the potential health benefits would be if the harmful effect of certain risk factors could be removed. What health benefits would arise from this, at which efforts and costs? To measure this the population attributive fraction (PAF) can be used. The PAF is expressed in a percentage and demonstrates the decrease of the percentage of incidences (number of new cases) when the harmful effects of the targeted risk factors are fully taken away. For public health it would be more effective to design an intervention targeted at a risk factor with a high PAF than a low PAF. […] An intervention needs to be effective in order to be implemented; this means that it has to show a statistically significant difference with placebo or other treatment. Secondly, it needs to be effective; it needs to prove its benefits also in real life (“everyday care”) circumstances. Thirdly, it needs to be efficient. The measure to address this is the Number Needed to Be Treated (NNT). The NNT expresses how many people need to be treated to prevent the onset of one new case with the disorder; the lower the number, the more efficient the intervention [45]. To summarize, an indicated preventative intervention would ideally be targeted at a relatively small group of people with a high, absolute chance of developing the disease, and a risk profile that is responsible for a high PAF. Furthermore, there needs to be an intervention that is both effective and efficient. […] a more detailed and specific description of the target group results in a higher absolute risk, a lower NNT, and also a lower PAF. This is helpful in determining the costs and benefits of interventions aiming at more specific or broader subgroups in the population. […] Unfortunately very large samples are required to demonstrate reductions in universal or selected interventions [46]. […] If the incidence rate is higher in the target population, which is usually the case in selective and even more so in indicated prevention, the number of participants needed to prove an effect is much smaller [5]. This shows that, even though universal interventions may be effective, its effect is harder to prove than that of indicated prevention. […] Indicated and selective preventions appear to be the most successful in preventing depression to date; however, more research needs to be conducted in larger samples to determine which prevention method is really most effective.”
“Groffen et al. [6] recently conducted an investigation among a sample of 4,809 participants from the Reykjavik Study (aged 66–93 years). Similar to the findings presented by Vink and colleagues [3], education level was related to depression risk: participants with lower education levels were more likely to report depressed mood in late-life than those with a college education (odds ratio [OR] = 1.87, 95 % confidence interval [CI] = 1.35–2.58). […] Results from a meta-analysis by Lorant and colleagues [8] showed that lower SES individuals had a greater odds of developing depression than those in the highest SES group (OR = 1.24, p= 0.004); however, the studies involved in this review did not focus on older populations. […] Cole and Dendukuri [10] performed a meta-analysis of studies involving middle-aged and older adult community residents, and determined that female gender was a risk factor for depression in this population (Pooled OR = 1.4, 95 % CI = 1.2–1.8), but not old age. Blazer and colleagues [11] found a significant positive association between older age and depressive symptoms in a sample consisting of community-dwelling older adults; however, when potential confounders such as physical disability, cognitive impairment, and gender were included in the analysis, the relationship between chronological age and depressive symptoms was reversed (p< 0.01). A study by Schoevers and colleagues [14] had similar results […] these findings suggest that higher incidence of depression observed among the oldest-old may be explained by other relevant factors. By contrast, the association of female gender with increased risk of late-life depression has been observed to be a highly consistent finding.”
“In an examination of marital bereavement, Turvey et al. [16] analyzed data among 5,449 participants aged≥70 years […] recently bereaved participants had nearly nine times the odds of developing syndromal depression as married participants (OR = 8.8, 95 % CI = 5.1–14.9, p<0.0001), and they also had significantly higher risk of depressive symptoms 2 years after the spousal loss. […] Caregiving burden is well-recognized as a predisposing factor for depression among older adults [18]. Many older persons are coping with physically and emotionally challenging caregiving roles (e.g., caring for a spouse/partner with a serious illness or with cognitive or physical decline). Additionally, many caregivers experience elements of grief, as they mourn the loss of relationship with or the decline of valued attributes of their care recipients. […] Concepts of social isolation have also been examined with regard to late-life depression risk. For example, among 892 participants aged ≥65 years […], Gureje et al. [13] found that women with a poor social network and rural residential status were more likely to develop major depressive disorder […] Harlow and colleagues [21] assessed the association between social network and depressive symptoms in a study involving both married and recently widowed women between the ages of 65 and 75 years; they found that number of friends at baseline had an inverse association with CES-D (Centers for Epidemiologic Studies Depression Scale) score after 1 month (p< 0.05) and 12 months (p= 0.06) of follow-up. In a study that explicitly addressed the concept of loneliness, Jaremka et al. [22] conducted a study relating this factor to late-life depression; importantly, loneliness has been validated as a distinct construct, distinguishable among older adults from depression. Among 229 participants (mean age = 70 years) in a cohort of older adults caring for a spouse with dementia, loneliness (as measured by the NYU scale) significantly predicted incident depression (p<0.001). Finally, social support has been identified as important to late-life depression risk. For example, Cui and colleagues [23] found that low perceived social support significantly predicted worsening depression status over a 2-year period among 392 primary care patients aged 65 years and above.”
“Saunders and colleagues [26] reported […] findings with alcohol drinking behavior as the predictor. Among 701 community-dwelling adults aged 65 years and above, the authors found a significant association between prior heavy alcohol consumption and late-life depression among men: compared to those who were not heavy drinkers, men with a history of heavy drinking had a nearly fourfold higher odds of being diagnosed with depression (OR = 3.7, 95 % CI = 1.3–10.4, p< 0.05). […] Almeida et al. found that obese men were more likely than non-obese (body mass index [BMI] < 30) men to develop depression (HR = 1.31, 95 % CI = 1.05–1.64). Consistent with these results, presence of the metabolic syndrome was also found to increase risk of incident depression (HR = 2.37, 95 % CI = 1.60–3.51). Finally, leisure-time activities are also important to study with regard to late-life depression risk, as these too are readily modifiable behaviors. For example, Magnil et al. [30] examined such activities among a sample of 302 primary care patients aged ≥60 years. The authors observed that those who lacked leisure activities had an increased risk of developing depressive symptoms over the 2-year study period (OR = 12, 95 % CI = 1.1–136, p= 0.041). […] an important future direction in addressing social and behavioral risk factors in late-life depression is to make more progress in trials that aim to alter those risk factors that are actually modifiable.”
Depression (II)
I have added some more quotes from the last half of the book as well as some more links to relevant topics below.
…
“The early drugs used in psychiatry were sedatives, as calming a patient was probably the only treatment that was feasible and available. Also, it made it easier to manage large numbers of individuals with small numbers of staff at the asylum. Morphine, hyoscine, chloral, and later bromide were all used in this way. […] Insulin coma therapy came into vogue in the 1930s following the work of Manfred Sakel […] Sakel initially proposed this treatment as a cure for schizophrenia, but its use gradually spread to mood disorders to the extent that asylums in Britain opened so-called insulin units. […] Recovery from the coma required administration of glucose, but complications were common and death rates ranged from 1–10 per cent. Insulin coma therapy was initially viewed as having tremendous benefits, but later re-examinations have highlighted that the results could also be explained by a placebo effect associated with the dramatic nature of the process or, tragically, because deprivation of glucose supplies to the brain may have reduced the person’s reactivity because it had induced permanent damage.”
“[S]ome respected scientists and many scientific journals remain ambivalent about the empirical evidence for the benefits of psychological therapies. Part of the reticence appears to result from the lack of very large-scale clinical trials of therapies (compared to international, multi-centre studies of medication). However, a problem for therapy research is that there is no large-scale funding from big business for therapy trials […] It is hard to implement optimum levels of quality control in research studies of therapies. A tablet can have the same ingredients and be prescribed in almost exactly the same way in different treatment centres and different countries. If a patient does not respond to this treatment, the first thing we can do is check if they receive the right medication in the correct dose for a sufficient period of time. This is much more difficult to achieve with psychotherapy and fuels concerns about how therapy is delivered and potential biases related to researcher allegiance (i.e. clinical centres that invent a therapy show better outcomes than those that did not) and generalizability (our ability to replicate the therapy model exactly in a different place with different therapists). […] Overall, the ease of prescribing a tablet, the more traditional evidence-base for the benefits of medication, and the lack of availability of trained therapists in some regions means that therapy still plays second fiddle to medications in the majority of treatment guidelines for depression. […] The mainstay of treatments offered to individuals with depression has changed little in the last thirty to forty years. Antidepressants are the first-line intervention recommended in most clinical guidelines”.
“[W]hilst some cases of mild–moderate depression can benefit from antidepressants (e.g. chronic mild depression of several years’ duration can often respond to medication), it is repeatedly shown that the only group who consistently benefit from antidepressants are those with severe depression. The problem is that in the real world, most antidepressants are actually prescribed for less severe cases, that is, the group least likely to benefit; which is part of the reason why the argument about whether antidepressants work is not going to go away any time soon.”
“The economic argument for therapy can only be sustained if it is shown that the long-term outcome of depression (fewer relapses and better quality of life) is improved by receiving therapy instead of medication or by receiving both therapy and medication. Despite claims about how therapies such as CBT, behavioural activation, IPT, or family therapy may work, the reality is that many of the elements included in these therapies are the same as elements described in all the other effective therapies (sometimes referred to as empirically supported therapies). The shared elements include forming a positive working alliance with the depressed person, sharing the model and the plan for therapy with the patient from day one, and helping the patient engage in active problem-solving, etc. Given the degree of overlap, it is hard to make a real case for using one empirically supported therapy instead of another. Also, there are few predictors (besides symptom severity and personal preference) that consistently show who will respond to one of these therapies rather than to medication. […] One of the reasons for some scepticism about the value of therapies for treating depression is that it has proved difficult to demonstrate exactly what mediates the benefits of these interventions. […] despite the enthusiasm for mindfulness, there were fewer than twenty high-quality research trials on its use in adults with depression by the end of 2015 and most of these studies had fewer than 100 participants. […] exercise improves the symptoms of depression compared to no treatment at all, but the currently available studies on this topic are less than ideal (with many problems in the design of the study or sample of participants included in the clinical trial). […] Exercise is likely to be a better option for those individuals whose mood improves from participating in the experience, rather than someone who is so depressed that they feel further undermined by the process or feel guilty about ‘not trying hard enough’ when they attend the programme.”
“Research […] indicates that treatment is important and a study from the USA in 2005 showed that those who took the prescribed antidepressant medications had a 20 per cent lower rate of absenteeism than those who did not receive treatment for their depression. Absence from work is only one half of the depression–employment equation. In recent times, a new concept ‘presenteeism’ has been introduced to try to describe the problem of individuals who are attending their place of work but have reduced efficiency (usually because their functioning is impaired by illness). As might be imagined, presenteeism is a common issue in depression and a study in the USA in 2007 estimated that a depressed person will lose 5–8 hours of productive work every week because the symptoms they experience directly or indirectly impair their ability to complete work-related tasks. For example, depression was associated with reduced productivity (due to lack of concentration, slowed physical and mental functioning, loss of confidence), and impaired social functioning”.
“Health economists do not usually restrict their estimates of the cost of a disorder simply to the funds needed for treatment (i.e. the direct health and social care costs). A comprehensive economic assessment also takes into account the indirect costs. In depression these will include costs associated with employment issues (e.g. absenteeism and presenteeism; sickness benefits), costs incurred by the patient’s family or significant others (e.g. associated with time away from work to care for someone), and costs arising from premature death such as depression-related suicides (so-called mortality costs). […] Studies from around the world consistently demonstrate that the direct health care costs of depression are dwarfed by the indirect costs. […] Interestingly, absenteeism is usually estimated to be about one-quarter of the costs of presenteeism.”
…
Jakob Klaesi. António Egas Moniz. Walter Jackson Freeman II.
Electroconvulsive therapy.
Psychosurgery.
Vagal nerve stimulation.
Chlorpromazine. Imipramine. Tricyclic antidepressant. MAOIs. SSRIs. John Cade. Mogens Schou. Lithium carbonate.
Psychoanalysis. CBT.
Thomas Szasz.
Initial Severity and Antidepressant Benefits: A Meta-Analysis of Data Submitted to the Food and Drug Administration (Kirsch et al.).
Chronobiology. Chronobiotics. Melatonin.
Eric Kandel. BDNF.
The global burden of disease (Murray & Lopez) (the author discusses some of the data included in that publication).
Depression (I)
Below I have added some quotes and links related to the first half of this book.
…
Quotes:
“One of the problems encountered in any discussion of depression is that the word is used to mean different things by different people. For many members of the public, the term depression is used to describe normal sadness. In clinical practice, the term depression can be used to describe negative mood states, which are symptoms that can occur in a range of illnesses (e.g. individuals with psychosis may also report depressed mood). However, the term depression can also be used to refer to a diagnosis. When employed in this way it is meant to indicate that a cluster of symptoms have all occurred together, with the most common changes being in mood, thoughts, feelings, and behaviours. Theoretically, all these symptoms need to be present to make a diagnosis of depressive disorder.”
“The absence of any laboratory tests in psychiatry means that the diagnosis of depression relies on clinical judgement and the recognition of patterns of symptoms. There are two main problems with this. First, the diagnosis represents an attempt to impose a ‘present/absent’ or ‘yes/no’ classification on a problem that, in reality, is dimensional and varies in duration and severity. Also, many symptoms are likely to show some degree of overlap with pre-existing personality traits. Taken together, this means there is an ongoing concern about the point at which depression or depressive symptoms should be regarded as a mental disorder, that is, where to situate the dividing line on a continuum from health to normal sadness to illness. Second, for many years, there was a lack of consistent agreement on what combination of symptoms and impaired functioning would benefit from clinical intervention. This lack of consensus on the threshold for treatment, or for deciding which treatment to use, is a major source of problems to this day. […] A careful inspection of the criteria for identifying a depressive disorder demonstrates that diagnosis is mainly reliant on the cross-sectional assessment of the way the person presents at that moment in time. It is also emphasized that the current presentation should represent a change from the person’s usual state, as this step helps to begin the process of differentiating illness episodes from long-standing personality traits. Clarifying the longitudinal history of any lifetime problems can help also to establish, for example, whether the person has previously experienced mania (in which case their diagnosis will be revised to bipolar disorder), or whether they have a history of chronic depression, with persistent symptoms that may be less severe but are nevertheless very debilitating (this is usually called dysthymia). In addition, it is important to assess whether the person has another mental or physical disorder as well as these may frequently co-occur with depression. […] In the absence of diagnostic tests, the current classifications still rely on expert consensus regarding symptom profiles.”
“In summary, for a classification system to have utility it needs to be reliable and valid. If a diagnosis is reliable doctors will all make the same diagnosis when they interview patients who present with the same set of symptoms. If a diagnosis has predictive validity it means that it is possible to forecast the future course of the illness in individuals with the same diagnosis and to anticipate their likely response to different treatments. For many decades, the lack of reliability so undermined the credibility of psychiatric diagnoses that most of the revisions of the classification systems between the 1950s and 2010 focused on improving diagnostic reliability. However, insufficient attention has been given to validity and until this is improved, the criteria used for diagnosing depressive disorders will continue to be regarded as somewhat arbitrary […]. Weaknesses in the systems for the diagnosis and classification of depression are frequently raised in discussions about the existence of depression as a separate entity and concerns about the rationale for treatment. It is notable that general medicine uses a similar approach to making decisions regarding the health–illness dimension. For example, levels of blood pressure exist on a continuum. However, when an individual’s blood pressure measurement reaches a predefined level, it is reported that the person now meets the criteria specified for the diagnosis of hypertension (high blood pressure). Depending on the degree of variation from the norm or average values for their age and gender, the person will be offered different interventions. […] This approach is widely accepted as a rational approach to managing this common physical health problem, yet a similar ‘stepped care’ approach to depression is often derided.”
“There are few differences in the nature of the symptoms experienced by men and women who are depressed, but there may be gender differences in how their distress is expressed or how they react to the symptoms. For example, men may be more likely to become withdrawn rather than to seek support from or confide in other people, they may become more outwardly hostile and have a greater tendency to use alcohol to try to cope with their symptoms. It is also clear that it may be more difficult for men to accept that they have a mental health problem and they are more likely to deny it, delay seeking help, or even to refuse help. […] becoming unemployed, retirement, and loss of a partner and change of social roles can all be risk factors for depression in men. In addition, chronic physical health problems or increasing disability may also act as a precipitant. The relationship between physical illness and depression is complex. When people are depressed they may subjectively report that their general health is worse than that of other people; likewise, people who are ill or in pain may react by becoming depressed. Certain medical problems such as an under-functioning thyroid gland (hypothyroidism) may produce symptoms that are virtually indistinguishable from depression. Overall, the rate of depression in individuals with a chronic physical disease is almost three times higher than those without such problems.”
“A long-standing problem in gathering data about suicide is that many religions and cultures regard it as a sin or an illegal act. This has had several consequences. For example, coroners and other public officials often strive to avoid identifying suspicious deaths as a suicide, meaning that the actual rates of suicide may be under-reported.”
“In Beck’s [depression] model, it is proposed that an individual’s interpretations of events or experiences are encapsulated in automatic thoughts, which arise immediately following the event or even at the same time. […] Beck suggested that these automatic thoughts occur at a conscious level and can be accessible to the individual, although they may not be actively aware of them because they are not concentrating on them. The appraisals that occur in specific situations largely determine the person’s emotional and behavioural responses […] [I]n depression, the content of a person’s thinking is dominated by negative views of themselves, their world, and their future (the so-called negative cognitive triad). Beck’s theory suggests that the themes included in the automatic thoughts are generated via the activation of underlying cognitive structures, called dysfunctional beliefs (or cognitive schemata). All individuals develop a set of rules or ‘silent assumptions’ derived from early learning experiences. Whilst automatic thoughts are momentary, event-specific cognitions, the underlying beliefs operate across a variety of situations and are more permanent. Most of the underlying beliefs held by the average individual are quite adaptive and guide our attempts to act and react in a considered way. Individuals at risk of depression are hypothesized to hold beliefs that are maladaptive and can have an unhelpful influence on them. […] faulty information processing contributes to further deterioration in a person’s mood, which sets up a vicious cycle with more negative mood increasing the risk of negative interpretations of day-to-day life experiences and these negative cognitions worsening the depressed mood. Beck suggested that the underlying beliefs that render an individual vulnerable to depression may be broadly categorized into beliefs about being helpless or unlovable. […] Beliefs about ‘the self’ seem especially important in the maintenance of depression, particularly when connected with low or variable self-esteem.”
“[U]nidimensional models, such as the monoamine hypothesis or the social origins of depression model, are important building blocks for understanding depression. However, in reality there is no one cause and no single pathway to depression and […] multiple factors increase vulnerability to depression. Whether or not someone at risk of depression actually develops the disorder is partly dictated by whether they are exposed to certain types of life events, the perceived level of threat or distress associated with those events (which in turn is influenced by cognitive and emotional reactions and temperament), their ability to cope with these experiences (their resilience or adaptability under stress), and the functioning of their biological stress-sensitivity systems (including the thresholds for switching on their body’s stress responses).”
…
Some links:
Humorism. Marsilio Ficino. Thomas Willis. William Cullen. Philippe Pinel. Benjamin Rush. Emil Kraepelin. Karl Leonhard. Sigmund Freud.
Depression.
Relation between depression and sociodemographic factors.
Bipolar disorder.
Postnatal depression. Postpartum psychosis.
Epidemiology of suicide. Durkheim’s typology of suicide.
Suicide methods.
Reserpine.
Neuroendocrine hypothesis of depression. HPA (Hypothalamic–Pituitary–Adrenal) axis.
Cognitive behavioral therapy.
Coping responses.
Brown & Harris (1978).
5-HTTLPR.
Random stuff
I have almost stopped posting posts like these, which has resulted in the accumulation of a very large number of links and studies which I figured I might like to blog at some point. This post is mainly an attempt to deal with the backlog – I won’t cover the material in too much detail.
…
i. Do Bullies Have More Sex? The answer seems to be a qualified yes. A few quotes:
“Sexual behavior during adolescence is fairly widespread in Western cultures (Zimmer-Gembeck and Helfland 2008) with nearly two thirds of youth having had sexual intercourse by the age of 19 (Finer and Philbin 2013). […] Bullying behavior may aid in intrasexual competition and intersexual selection as a strategy when competing for mates. In line with this contention, bullying has been linked to having a higher number of dating and sexual partners (Dane et al. 2017; Volk et al. 2015). This may be one reason why adolescence coincides with a peak in antisocial or aggressive behaviors, such as bullying (Volk et al. 2006). However, not all adolescents benefit from bullying. Instead, bullying may only benefit adolescents with certain personality traits who are willing and able to leverage bullying as a strategy for engaging in sexual behavior with opposite-sex peers. Therefore, we used two independent cross-sectional samples of older and younger adolescents to determine which personality traits, if any, are associated with leveraging bullying into opportunities for sexual behavior.”
“…bullying by males signal the ability to provide good genes, material resources, and protect offspring (Buss and Shackelford 1997; Volk et al. 2012) because bullying others is a way of displaying attractive qualities such as strength and dominance (Gallup et al. 2007; Reijntjes et al. 2013). As a result, this makes bullies attractive sexual partners to opposite-sex peers while simultaneously suppressing the sexual success of same-sex rivals (Gallup et al. 2011; Koh and Wong 2015; Zimmer-Gembeck et al. 2001). Females may denigrate other females, targeting their appearance and sexual promiscuity (Leenaars et al. 2008; Vaillancourt 2013), which are two qualities relating to male mate preferences. Consequently, derogating these qualities lowers a rivals’ appeal as a mate and also intimidates or coerces rivals into withdrawing from intrasexual competition (Campbell 2013; Dane et al. 2017; Fisher and Cox 2009; Vaillancourt 2013). Thus, males may use direct forms of bullying (e.g., physical, verbal) to facilitate intersexual selection (i.e., appear attractive to females), while females may use relational bullying to facilitate intrasexual competition, by making rivals appear less attractive to males.”
The study relies on the use of self-report data, which I find very problematic – so I won’t go into the results here. I’m not quite clear on how those studies mentioned in the discussion ‘have found self-report data [to be] valid under conditions of confidentiality’ – and I remain skeptical. You’ll usually want data from independent observers (e.g. teacher or peer observations) when analyzing these kinds of things. Note in the context of the self-report data problem that if there’s a strong stigma associated with being bullied (there often is, or bullying wouldn’t work as well), asking people if they have been bullied is not much better than asking people if they’re bullying others.
…
ii. Some topical advice that some people might soon regret not having followed, from the wonderful Things I Learn From My Patients thread:
“If you are a teenage boy experimenting with fireworks, do not empty the gunpowder from a dozen fireworks and try to mix it in your mother’s blender. But if you do decide to do that, don’t hold the lid down with your other hand and stand right over it. This will result in the traumatic amputation of several fingers, burned and skinned forearms, glass shrapnel in your face, and a couple of badly scratched corneas as a start. You will spend months in rehab and never be able to use your left hand again.”
…
iii. I haven’t talked about the AlphaZero-Stockfish match, but I was of course aware of it and did read a bit about that stuff. Here’s a reddit thread where one of the Stockfish programmers answers questions about the match. A few quotes:
Child psychology
I was not impressed with this book, but as mentioned in the short review it was ‘not completely devoid of observations of interest’.
Before I start my proper coverage of the book, here are some related ‘observations’ from a different book I recently read, Bellwether:
…
““First we’re all going to play a game. Bethany, it’s Brittany’s birthday.” She attempted a game involving balloons with pink Barbies on them and then gave up and let Brittany open her presents. “Open Sandy’s first,” Gina said, handing her the book.
“No, Caitlin, these are Brittany’s presents.”
Brittany ripped the paper off Toads and Diamonds and looked at it blankly.
“That was my favorite fairy tale when I was little,” I said. “It’s about a girl who meets a good fairy, only she doesn’t, know it because the fairy’s in disguise—” but Brittany had already tossed it aside and was ripping open a Barbie doll in a glittery dress.
“Totally Hair Barbie!” she shrieked.
“Mine,” Peyton said, and made a grab that left Brittany holding nothing but Barbie’s arm.
“She broke Totally Hair Barbie!” Brittany wailed.
Peyton’s mother stood up and said calmly, “Peyton, I think you need a time-out.”
I thought Peyton needed a good swat, or at least to have Totally Hair Barbie taken away from her and given back to Brittany, but instead her mother led her to the door of Gina’s bedroom. “You can come out when you’re in control of your feelings,” she said to Peyton, who looked like she was in control to me.
“I can’t believe you’re still using time-outs,” Chelsea’s mother said. “Everybody’s using holding now.”
“Holding?” I asked.
“You hold the child immobile on your lap until the negative behavior stops. It produces a feeling of interceptive safety.”
“Really,” I said, looking toward the bedroom door. I would have hated trying to hold Peyton against her will.
“Holding’s been totally abandoned,” Lindsay’s mother said. “We use EE.”
“EE?” I said.
“Esteem Enhancement,” Lindsay’s mother said. “EE addresses the positive peripheral behavior no matter how negative the primary behavior is.”
“Positive peripheral behavior?” Gina said dubiously. “When Peyton took the Barbie away from Brittany just now,” Lindsay’s mother said, obviously delighted to explain, “you would have said, ‘My, Peyton, what an assertive grip you have.’”
[A little while later, during the same party:]
“My, Peyton,” Lindsay’s mother said, “what a creative thing to do with your frozen yogurt.””
…
Okay, on to the coverage of the book. I haven’t covered it in much detail, but I have included some observations of interest below.
…
“[O]ptimal development of grammar (knowledge about language structure) and phonology (knowledge about the sound elements in words) depends on the brain experiencing sufficient linguistic input. So quantity of language matters. The quality of the language used with young children is also important. The easiest way to extend the quality of language is with interactions around books. […] Natural conversations, focused on real events in the here and now, are those which are critical for optimal development. Despite this evidence, just talking to young children is still not valued strongly in many environments. Some studies find that over 60 per cent of utterances to young children are ‘empty language’ — phrases such as ‘stop that’, ‘don’t go there’, and ‘leave that alone’. […] studies of children who experience high levels of such ‘restricted language’ reveal a negative impact on later cognitive, social, and academic development.”
[Neural] plasticity is largely achieved by the brain growing connections between brain cells that are already there. Any environmental input will cause new connections to form. At the same time, connections that are not used much will be pruned. […] the consistency of what is experienced will be important in determining which connections are pruned and which are retained. […] Brains whose biology makes them less efficient in particular and measurable aspects of processing seem to be at risk in specific areas of development. For example, when auditory processing is less efficient, this can carry a risk of later language impairment.”
“Joint attention has […] been suggested to be the basis of ‘natural pedagogy’ — a social learning system for imparting cultural knowledge. Once attention is shared by adult and infant on an object, an interaction around that object can begin. That interaction usually passes knowledge from carer to child. This is an example of responsive contingency in action — the infant shows an interest in something, the carer responds, and there is an interaction which enables learning. Taking the child’s focus of attention as the starting point for the interaction is very important for effective learning. Of course, skilled carers can also engineer situations in which babies or children will become interested in certain objects. This is the basis of effective play-centred learning. Novel toys or objects are always interesting.”
“Some research suggests that the pitch and amplitude (loudness) of a baby’s cry has been developed by evolution to prompt immediate action by adults. Babies’ cries appear to be designed to be maximally stressful to hear.”
“[T]he important factors in becoming a ‘preferred attachment figure’ are proximity and consistency.”
“[A]dults modify their actions in important ways when they interact with infants. These modifications appear to facilitate learning. ‘Infant-directed action’ is characterized by greater enthusiasm, closer proximity to the infant, greater repetitiveness, and longer gaze to the face than interactions with another adult. Infant-directed action also uses simplified actions with more turn-taking. […] carers tend to use a special tone of voice to talk to babies. This is more sing-song and attention-grabbing than normal conversational speech, and is called ‘infant-directed speech’ [IDS] or ‘Parentese’. All adults and children naturally adopt this special tone when talking to a baby, and babies prefer to listen to Parentese. […] IDS […] heightens pitch, exaggerates the length of words, and uses extra stress, exaggerating the rhythmic or prosodic aspects of speech. […] the heightened prosody increases the salience of acoustic cues to where words begin and end. […] So as well as capturing attention, IDS is emphasizing key linguistic cues that help language acquisition. […] The infant brain seems to cope with the ‘learning problem’ of which sounds matter by initially being sensitive to all the sound elements used by the different world languages. Via acoustic learning during the first year of life, the brain then specializes in the sounds that matter for the particular languages that it is being exposed to.”
“While crawling makes it difficult to carry objects with you on your travels, learning to walk enables babies to carry things. Indeed, walking babies spend most of their time selecting objects and taking them to show their carer, spending on average 30–40 minutes per waking hour interacting with objects. […] Self-generated movement is seen as critical for child development. […] most falling is adaptive, as it helps infants to gain expertise. Indeed, studies show that newly walking infants fall on average 17 times per hour. From the perspective of child psychology, the importance of ‘motor milestones’ like crawling and walking is that they enable greater agency (self-initiated and self-chosen behaviour) on the part of the baby.”
“Statistical learning enables the brain to learn the statistical structure of any event or object. […] Statistical structure is learned in all sensory modalities simultaneously. For example, as the child learns about birds, the child will learn that light body weight, having feathers, having wings, having a beak, singing, and flying, all go together. Each bird that the child sees may be different, but each bird will share the features of flying, having feathers, having wings, and so on. […] The connections that form between the different brain cells that are activated by hearing, seeing, and feeling birds will be repeatedly strengthened for these shared features, thereby creating a multi-modal neural network for that particular concept. The development of this network will be dependent on everyday experiences, and the networks will be richer if the experiences are more varied. This principle of learning supports the use of multi-modal instruction and active experience in nursery and primary school. […] knowledge about concepts is distributed across the entire brain. It is not stored separately in a kind of conceptual ‘dictionary’ or distinct knowledge system. Multi-modal experiences strengthen learning across the whole brain. Accordingly, multisensory learning is the most effective kind of learning for young children.”
“Babies learn words most quickly when an adult both points to and names a new item.”
“…direct teaching of scientific reasoning skills helps children to reason logically independently of their pre-existing beliefs. This is more difficult than it sounds, as pre-existing beliefs exert strong effects. […] in many social situations we are advantaged if we reason on the basis of our pre-existing beliefs. This is one reason that stereotypes form”. [Do remember on a related note that stereotype accuracy is one of the largest and most replicable effects in all of social psychology – US].
“Some gestures have almost universal meaning, like waving goodbye. Babies begin using gestures like this quite early on. Between 10 and 18 months of age, gestures become frequent and are used extensively for communication. […] After around 18 months, the use of gesture starts declining, as vocalization becomes more and more dominant in communication. […] By [that time], most children are entering the two-word stage, when they become able to combine words. […] At this age, children often use a word that they know to refer to many different entities whose names are not yet known. They might use the word ‘bee’ for insects that are not bees, or the word ‘dog’ to refer to horses and cows. Experiments have shown that this is not a semantic confusion. Toddlers do not think that horses and cows are a type of dog. Rather, they have limited language capacities, and so they stretch their limited vocabularies to communicate as flexibly as possible. […] there is a lot of similarity across cultures at the two-word stage regarding which words are combined. Young children combine words to draw attention to objects (‘See doggie!’), to indicate ownership (‘My shoe’), to point out properties of objects (‘Big doggie’), to indicate plurality (‘Two cookie’), and to indicate recurrence (‘Other cookie’). […] It is only as children learn grammar that some divergence is found across languages. This is probably because different languages have different grammatical formats for combining words. […] grammatical learning emerges naturally from extensive language experience (of the utterances of others) and from language use (the novel utterances of the child, which are re-formulated by conversational partners if they are grammatically incorrect).”
“The social and communicative functions of language, and children’s understanding of them, are captured by pragmatics. […] pragmatic aspects of conversation include taking turns, and making sure that the other person has sufficient knowledge of the events being discussed to follow what you are saying. […] To learn about pragmatics, children need to go beyond the literal meaning of the words and make inferences about communicative intent. A conversation is successful when a child has recognized the type of social situation and applied the appropriate formula. […] Children with autism, who have difficulties with social cognition and in reading the mental states of others, find learning the pragmatics of conversation particularly difficult. […] Children with autism often show profound delays in social understanding and do not ‘get’ many social norms. These children may behave quite inappropriately in social settings […] Children with autism may also show very delayed understanding of emotions and of intentions. However, this does not make them anti-social, rather it makes them relatively ineffective at being pro-social.”
“When children have siblings, there are usually developmental advantages for social cognition and psychological understanding. […] Discussing the causes of disputes appears to be particularly important for developing social understanding. Young children need opportunities to ask questions, argue with explanations, and reflect on why other people behave in the way that they do. […] Families that do not talk about the intentions and emotions of others and that do not explicitly discuss social norms will create children with reduced social understanding.”
“[C]hildren, like adults, are more likely to act in pro-social ways to ingroup members. […] Social learning of cultural ‘ingroups’ appears to develop early in children as part of general socio-moral development. […] being loyal to one’s ‘ingroup’ is likely to make the child more popular with the other members of that group. Being in a group thus requires the development of knowledge about how to be loyal, about conforming to pressure and about showing ingroup bias. For example, children may need to make fine judgements about who is more popular within the group, so that they can favour friends who are more likely to be popular with the rest of the group. […] even children as young as 6 years will show more positive responding to the transgression of social rules by ingroup members compared to outgroup members, particularly if they have relatively well-developed understanding of emotions and intentions.”
“Good language skills improve memory, because children with better language skills are able to construct narratively coherent and extended, temporally organized representations of experienced events.”
“Once children begin reading, […] letter-sound knowledge and ‘phonemic awareness’ (the ability to divide words into the single sound elements represented by letters) become the most important predictors of reading development. […] phonemic awareness largely develops as a consequence of being taught to read and write. Research shows that illiterate adults do not have phonemic awareness. […] brain imaging shows that learning to read ‘re-maps’ phonology in the brain. We begin to hear words as sequences of ‘phonemes’ only after we learn to read.”
A few diabetes papers of interest
“Children and youth with type 1 diabetes are at risk for developing neurocognitive dysfunction, especially in the areas of psychomotor speed, attention/executive functioning, and visuomotor integration (1,2). Most research suggests that deficits emerge over time, perhaps in response to the cumulative effect of glycemic extremes (3–6). However, the idea that cognitive changes emerge gradually has been challenged (7–9). Ryan (9) argued that if diabetes has a cumulative effect on cognition, cognitive test performance should be positively correlated with illness duration. Yet he found comparable deficits in psychomotor speed (the most commonly noted area of deficit) in adolescents and young adults with illness duration ranging from 6 to 25 years. He therefore proposed a diathesis model in which cognitive declines in diabetes are especially likely to occur in more vulnerable patients, at crucial periods, in response to illness-related events (e.g., severe hyperglycemia) known to have an impact on the central nervous system (CNS) (8). This model accounts for the finding that cognitive deficits are more likely in children with early-onset diabetes, and for the accelerated cognitive aging seen in diabetic individuals later in life (7). A third hypothesized crucial period is the time leading up to diabetes diagnosis, during which severe fluctuations in blood glucose and persistent hyperglycemia often occur. Concurrent changes in blood-brain barrier permeability could result in a flood of glucose into the brain, with neurotoxic effects (9).”
“In the current study, we report neuropsychological test findings for children and adolescents tested within 3 days of diabetes diagnosis. The purpose of the study was to determine whether neurocognitive impairments are detectable at diagnosis, as predicted by the diathesis hypothesis. We hypothesized that performance on tests of psychomotor speed, visuomotor integration, and attention/executive functioning would be significantly below normative expectations, and that differences would be greater in children with earlier disease onset. We also predicted that diabetic ketoacidosis (DKA), a primary cause of diabetes-related neurological morbidity (12) and a likely proxy for severe peri-onset hyperglycemia, would be associated with poorer performance.”
“Charts were reviewed for 147 children/adolescents aged 5–18 years (mean = 10.4 ± 3.2 years) who completed a short neuropsychological screening during their inpatient hospitalization for new-onset type 1 diabetes, as part of a pilot clinical program intended to identify patients in need of further neuropsychological evaluation. Participants were patients at a large urban children’s hospital in the southwestern U.S. […] Compared with normative expectations, children/youth with type 1 diabetes performed significantly worse on GPD, GPN, VMI, and FAS (P < 0.0001 in all cases), with large decrements evident on all four measures (Fig. 1). A small but significant effect was also evident in DSB (P = 0.022). High incidence of impairment was evident on all neuropsychological tasks completed by older participants (aged 9–18 years) except DSF/DSB (Fig. 2).”
“Deficits in neurocognitive functioning were evident in children and adolescents within days of type 1 diabetes diagnosis. Participants performed >1 SD below normative expectations in bilateral psychomotor speed (GP) and 0.7–0.8 SDs below expected performance in visuomotor integration (VMI) and phonemic fluency (FAS). Incidence of impairment was much higher than normative expectations on all tasks except DSF/DSB. For example, >20% of youth were impaired in dominant hand fine-motor control, and >30% were impaired with their nondominant hand. These findings provide provisional support for Ryan’s hypothesis (7–9) that the peri-onset period may be a time of significant cognitive vulnerability.
Importantly, deficits were not evident on all measures. Performance on measures of attention/executive functioning (TMT-A, TMT-B, DSF, and DSB) was largely consistent with normative expectations, as was reading ability (WRAT-4), suggesting that the below-average performance in other areas was not likely due to malaise or fatigue. Depressive symptoms at diagnosis were associated with performance on TMT-B and FAS, but not on other measures. Thus, it seems unlikely that depressive symptoms accounted for the observed motor slowing.
Instead, the findings suggest that the visual-motor system may be especially vulnerable to early effects of type 1 diabetes. This interpretation is especially compelling given that psychomotor impairment is the most consistently reported long-term cognitive effect of type 1 diabetes. The sensitivity of the visual-motor system at diabetes diagnosis is consistent with a growing body of neuroimaging research implicating posterior white matter tracts and associated gray matter regions (particularly cuneus/precuneus) as areas of vulnerability in type 1 diabetes (30–32). These regions form part of the neural system responsible for integrating visual inputs with motor outputs, and in adults with type 1 diabetes, structural pathology in these regions is directly correlated to performance on GP [grooved pegboard test] (30,31). Arbelaez et al. (33) noted that these brain areas form part of the “default network” (34), a system engaged during internally focused cognition that has high resting glucose metabolism and may be especially vulnerable to glucose variability.”
“It should be noted that previous studies (e.g., Northam et al. [3]) have not found evidence of neurocognitive dysfunction around the time of diabetes diagnosis. This may be due to study differences in measures, outcomes, and/or time frame. We know of no other studies that completed neuropsychological testing within days of diagnosis. Given our time frame, it is possible that our findings reflect transient effects rather than more permanent changes in the CNS. Contrary to predictions, we found no association between DKA at diagnosis and neurocognitive performance […] However, even transient effects could be considered potential indicators of CNS vulnerability. Neurophysiological changes at the time of diagnosis have been shown to persist under certain circumstances or for some patients. […] [Some] findings suggest that some individuals may be particularly susceptible to the effects of glycemic extremes on neurocognitive function, consistent with a large body of research in developmental neuroscience indicating individual differences in neurobiological vulnerability to adverse events. Thus, although it is possible that the neurocognitive impairments observed in our study might resolve with euglycemia, deficits at diagnosis could still be considered a potential marker of CNS vulnerability to metabolic perturbations (both acute and chronic).”
“In summary, this study provides the first demonstration that type 1 diabetes–associated neurocognitive impairment can be detected at the time of diagnosis, supporting the possibility that deficits arise secondary to peri-onset effects. Whether these effects are transient markers of vulnerability or represent more persistent changes in CNS awaits further study.”
…
“Cardiovascular autonomic neuropathy (CAN) is a chronic complication of diabetes and an independent predictor of cardiovascular disease (CVD) morbidity and mortality (1–3). The mechanisms of CAN are complex and not fully understood. It can be assessed by simple cardiovascular reflex tests (CARTs) and heart rate variability (HRV) studies that were shown to be sensitive, noninvasive, and reproducible (3,4).”
“HbA1c fails to capture information on the daily fluctuations in blood glucose levels, termed glycemic variability (GV). Recent observations have fostered the notion that GV, independent of HbA1c, may confer an additional risk for the development of micro- and macrovascular diabetes complications (8,9). […] the relationship between GV and chronic complications, specifically CAN, in patients with type 1 diabetes has not been systematically studied. In addition, limited data exist on the relationship between hypoglycemic components of the GV and measures of CAN among subjects with type 1 diabetes (11,12). Therefore, we have designed a prospective study to evaluate the impact and the possible sustained effects of GV on measures of cardiac autonomic function and other cardiovascular complications among subjects with type 1 diabetes […] In the present communication, we report cross-sectional analyses at baseline between indices of hypoglycemic stress on measures of cardiac autonomic function.”
“The following measures of CAN were predefined as outcomes of interests and analyzed: expiration-to-inspiration ratio (E:I), Valsalva ratio, 30:15 ratios, low-frequency (LF) power (0.04 to 0.15 Hz), high-frequency (HF) power (0.15 to 0.4 Hz), and LF/HF at rest and during CARTs. […] We found that LBGI [low blood glucose index] and AUC [area under the curve] hypoglycemia were associated with reduced LF and HF power of HRV [heart rate variability], suggesting an impaired autonomic function, which was independent of glucose control as assessed by the HbA1c.”
“Our findings are in concordance with a recent report demonstrating attenuation of the baroreflex sensitivity and of the sympathetic response to various cardiovascular stressors after antecedent hypoglycemia among healthy subjects who were exposed to acute hypoglycemic stress (18). Similar associations […] were also reported in a small study of subjects with type 2 diabetes (19). […] higher GV and hypoglycemic stress may have an acute effect on modulating autonomic control with inducing a sympathetic/vagal imbalance and a blunting of the cardiac vagal control (18). The impairment in the normal counter-regulatory autonomic responses induced by hypoglycemia on the cardiovascular system could be important in healthy individuals but may be particularly detrimental in individuals with diabetes who have hitherto compromised cardiovascular function and/or subclinical CAN. In these individuals, hypoglycemia may also induce QT interval prolongation, increase plasma catecholamine levels, and lower serum potassium (19,20). In concert, these changes may lower the threshold for serious arrhythmia (19,20) and could result in an increased risk of cardiovascular events and sudden cardiac death. Conversely, the presence of CAN may increase the risk of hypoglycemia through hypoglycemia unawareness and subsequent impaired ability to restore euglycemia (21) through impaired sympathoadrenal response to hypoglycemia or delayed gastric emptying. […] A possible pathogenic role of GV/hypoglycemic stress on CAN development and progressions should be also considered. Prior studies in healthy and diabetic subjects have found that higher exposure to hypoglycemia reduces the counter-regulatory hormone (e.g., epinephrine, glucagon, and adrenocorticotropic hormone) and blunts autonomic nervous system responses to subsequent hypoglycemia (21). […] Our data […] suggest that wide glycemic fluctuations, particularly hypoglycemic stress, may increase the risk of CAN in patients with type 1 diabetes.”
“In summary, in this cohort of relatively young and uncomplicated patients with type 1 diabetes, GV and higher hypoglycemic stress were associated with impaired HRV reflective of sympathetic/parasympathetic dysfunction with potential important clinical consequences.”
…
“In the last decade, several studies have been published that suggest a close association between diabetes and depression. Patients with diabetes have a high prevalence of depression (1) […] and a high prevalence of complications (3). In addition, depression is associated with mortality in these patients (4). […] Because of this strong association, several recent studies have suggested the possibility of a common biological pathway such as inflammation as an underlying mechanism of the association between depression and diabetes (5). […] Multiple mechanisms are involved in the association between diabetes and inflammation, including modulation of lipolysis, alteration of glucose uptake by adipose tissue, and an indirect mechanism involving an increase in free fatty acid levels blocking the insulin signaling pathway (10). Psychological stress can also cause inflammation via innervation of cytokine-producing cells and activation of the sympathetic nervous systems and adrenergic receptors on macrophages (11). Depression enhances the production of inflammatory cytokines (12–14). Overproduction of inflammatory cytokines may stimulate corticotropin-releasing hormone production, a mechanism that leads to hypothalamic-pituitary axis activity. Conversely, cytokines induce depressive-like behaviors; in studies where healthy participants were given endotoxin infusions to trigger cytokine release, the participants developed classic depressive symptoms (15). Based on this evidence, it could be hypothesized that inflammation is the common biological pathway underlying the association between diabetes and depression.”
“[F]ew studies have examined the clinical role of inflammation and depression as biological correlates in patients with diabetes. […] In this study, we hypothesized that high CRP [C-reactive protein] levels were associated with the high prevalence of depression in patients with diabetes and that this association may be modified by obesity or glycemic control. […] Patient data were derived from the second-year survey of a diabetes registry at Tenri Hospital, a regional tertiary care teaching hospital in Japan. […] 3,573 patients […] were included in the study. […] Overall, mean age, HbA1c level, and BMI were 66.0 years, 7.4% (57.8 mmol/mol), and 24.6 kg/m2, respectively. Patients with major depression tended to be relatively young […] and female […] with a high BMI […], high HbA1c levels […], and high hs-CRP levels […]; had more diabetic nephropathy […], required more insulin therapy […], and exercised less […]”.
“In conclusion, we observed that hs-CRP levels were associated with a high prevalence of major depression in patients with type 2 diabetes with a BMI of ≥25 kg/m2. […] In patients with a BMI of <25 kg/m2, no significant association was found between hs-CRP quintiles and major depression […] We did not observe a significant association between hs-CRP and major depression in either of HbA1c subgroups. […] Our results show that the association between hs-CRP and diabetes is valid even in an Asian population, but it might not be extended to nonobese subjects. […] several factors such as obesity and glycemic control may modify the association between inflammation and depression. […] Obesity is strongly associated with chronic inflammation.”
…
iv. A Novel Association Between Nondipping and Painful Diabetic Polyneuropathy.
“Sleep problems are common in painful diabetic polyneuropathy (PDPN) (1) and contribute to the effect of pain on quality of life. Nondipping (the absence of the nocturnal fall in blood pressure [BP]) is a recognized feature of diabetic cardiac autonomic neuropathy (CAN) and is attributed to the abnormal prevalence of nocturnal sympathetic activity (2). […] This study aimed to evaluate the relationship of the circadian pattern of BP with both neuropathic pain and pain-related sleep problems in PDPN […] Investigating the relationship between PDPN and BP circadian pattern, we found patients with PDPN exhibited impaired nocturnal decrease in BP compared with those without neuropathy, as well as higher nocturnal systolic BP than both those without DPN and with painless DPN. […] in multivariate analysis including comorbidities and most potential confounders, neuropathic pain was an independent determinant of ∆ in BP and nocturnal systolic BP.”
“PDPN could behave as a marker for the presence and severity of CAN. […] PDPN should increasingly be regarded as a condition of high cardiovascular risk.”
…
I think a potentially important take-away from this paper, which they don’t really talk about, is that when you’re analyzing time series data in research contexts where the HbA1c variable is available at the individual level at some base frequency and you then encounter individuals for whom the HbA1c variable is unobserved in such a data set for some time periods/is not observed at the frequency you’d expect, such (implicit) missing values may not be missing at random (for more on these topics see e.g. this post). More specifically, in light of the findings of this paper I think it would make a lot of sense to default to an assumption of missing values being an indicator of worse-than-average metabolic control during the unobserved period of the time series in question when doing time-to-event analyses, especially in contexts where the values are missing for an extended period of time.
The authors of the paper consider metabolic control an outcome to be explained by the testing frequency. That’s one way to approach these things, but it’s not the only one and I think it’s also important to keep in mind that some patients also sometimes make a conscious decision not to show up for their appointments/tests; i.e. the testing frequency is not necessarily fully determined by the medical staff, although they of course have an important impact on this variable.
Some observations from the paper:
“We examined repeat HbA1c tests (400,497 tests in 79,409 patients, 2008–2011) processed by three U.K. clinical laboratories. We examined the relationship between retest interval and 1) percentage change in HbA1c and 2) proportion of cases showing a significant HbA1c rise. The effect of demographics factors on these findings was also explored. […] Figure 1 shows the relationship between repeat requesting interval (categorized in 1-month intervals) and percentage change in HbA1c concentration in the total data set. From 2 months onward, there was a direct relationship between retesting interval and control. A testing frequency of >6 months was associated with deterioration in control. The optimum testing frequency in order to maximize the downward trajectory in HbA1c between two tests was approximately four times per year. Our data also indicate that testing more frequently than 2 months has no benefit over testing every 2–4 months. Relative to the 2–3 month category, all other categories demonstrated statistically higher mean change in HbA1c (all P < 0.001). […] similar patterns were observed for each of the three centers, with the optimum interval to improvement in overall control at ∼3 months across all centers.”
“[I]n patients with poor control, the pattern was similar to that seen in the total group, except that 1) there was generally a more marked decrease or more modest increase in change of HbA1c concentration throughout and, consequently, 2) a downward trajectory in HbA1c was observed when the interval between tests was up to 8 months, rather than the 6 months as seen in the total group. In patients with a starting HbA1c of <6% (<42 mmol/mol), there was a generally linear relationship between interval and increase in HbA1c, with all intervals demonstrating an upward change in mean HbA1c. The intermediate group showed a similar pattern as those with a starting HbA1c of <6% (<42 mmol/mol), but with a steeper slope.”
“In order to examine the potential link between monitoring frequency and the risk of major deterioration in control, we then assessed the relationship between testing interval and proportion of patients demonstrating an increase in HbA1c beyond the normal biological and analytical variation in HbA1c […] Using this definition of significant increase as a ≥9.9% rise in subsequent HbA1c, our data show that the proportion of patients showing this magnitude of rise increased month to month, with increasing intervals between tests for each of the three centers. […] testing at 2–3-monthly intervals would, at a population level, result in a marked reduction in the proportion of cases demonstrating a significant increase compared with annual testing […] irrespective of the baseline HbA1c, there was a generally linear relationship between interval and the proportion demonstrating a significant increase in HbA1c, though the slope of this relationship increased with rising initial HbA1c.”
“Previous data from our and other groups on requesting patterns indicated that relatively few patients in general practice were tested annually (5,6). […] Our data indicate that for a HbA1c retest interval of more than 2 months, there was a direct relationship between retesting interval and control […], with a retest frequency of greater than 6 months being associated with deterioration in control. The data showed that for diabetic patients as a whole, the optimum repeat testing interval should be four times per year, particularly in those with poorer diabetes control (starting HbA1c >7% [≥53 mmol/mol]). […] The optimum retest interval across the three centers was similar, suggesting that our findings may be unrelated to clinical laboratory factors, local policies/protocols on testing, or patient demographics.”
It might be important to mention that there are important cross-country differences in terms of how often people with diabetes get HbA1c measured – I’m unsure of whether or not standards have changed since then, but at least in Denmark a specific treatment goal of the Danish Regions a few years ago was whether or not 95% of diabetics had had their HbA1c measured within the last year (here’s a relevant link to some stuff I wrote about related topics a while back).
Recent Comments
Sabra Zaraa on Cost-effectiveness analysis in… adityaguharoy on Combinatorics (I) therookswinger on Magnus Carlsen playing bullet… Stefan on Quotes US on Quotes Goodreads Quotes
Usfromdk’s quotes
"Happiness and its anticipation are […] proximate mechanisms that lead us to perform and repeat acts that in the environments of history, at least, would have led to greater reproductive success." (Richard D. Alexander)Statcounter
